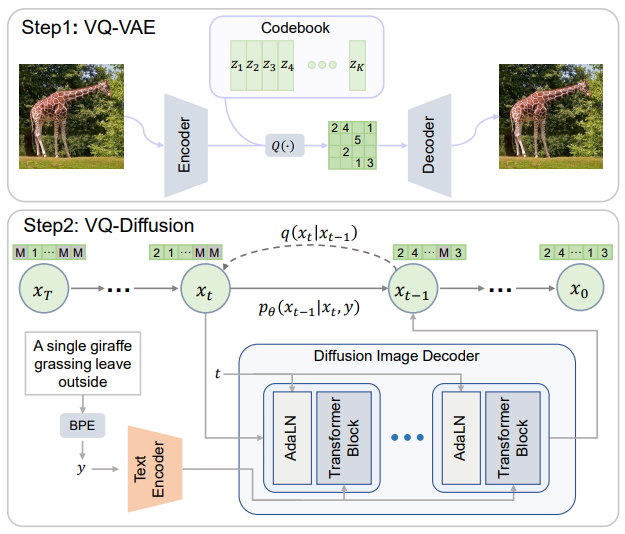
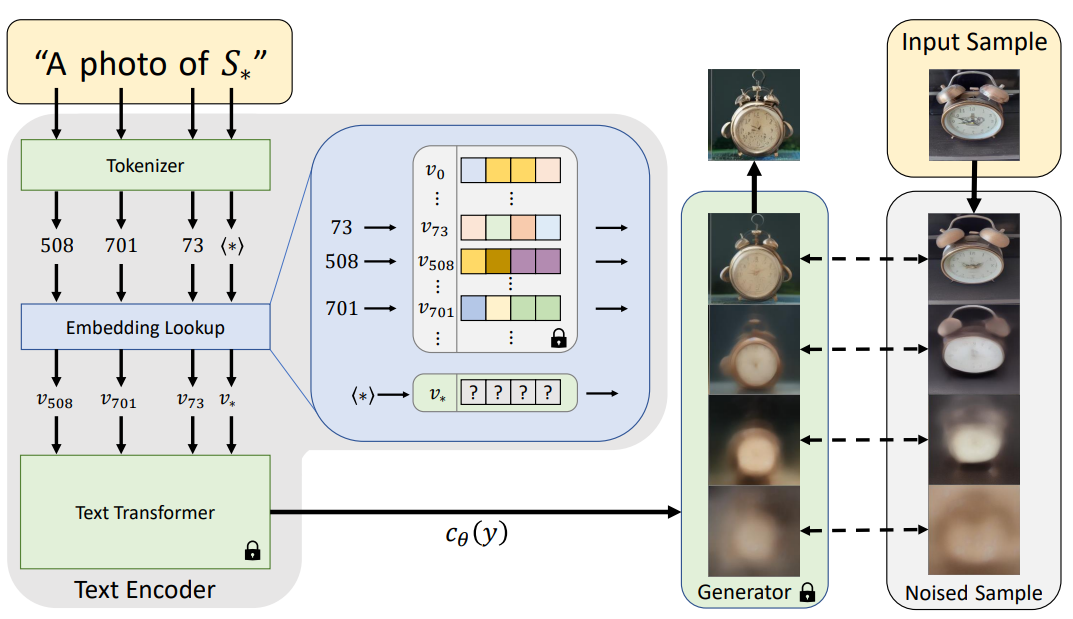
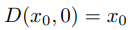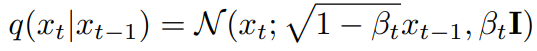뉴럴 네트워크의 기초: 완벽 가이드 1. 뉴럴 네트워크란?1.1 기본 개념뉴럴 네트워크를 이해하기 위해 먼저 선형 분류기를 살펴보겠습니다. 기존의 선형 분류에서는 다음과 같은 공식을 사용했습니다:s = Wx # 여기서 s는 점수, W는 가중치 행렬, x는 입력 벡터예를 들어 CIFAR-10 데이터셋의 경우:x: [3072x1] 크기의 이미지 픽셀 데이터 벡터W: [10x3072] 크기의 가중치 행렬s: 10개 클래스에 대한 점수 벡터1.2 뉴럴 네트워크의 기본 수식기본적인 뉴럴 네트워크는 다음과 같은 형태를 가집니다:s = W2 * max(0, W1x)여기서:W1: [100x3072] 크기의 첫 번째 가중치 행렬max(0,-): ReLU 활성화 함수W2: [10x100] 크기의 두 번째 가중치 행렬3층 ..