Link
- 프로젝트 링크 https://imagen.research.google/
Abstract
전례 없는 수준의 photorealism과 깊은 수준의 언어 이해를 갖춘 text-to-image 확산 모델인 Imagen을 제시합니다. Imagen은 대형 transformer 언어 모델의 힘을 기반으로 하며 사전 훈련된 일반 대형 언어 모델이 이미지 합성을 위한 텍스트 인코딩에 놀라울 정도로 효과적이라는 것을 발견했습니다.
Text-to-image 모델을 더욱 깊이 있게 평가하기 위해 포괄적이고 도전적인 벤치마크인 DrawBench를 소개한다.
Introduction
Text-to-image 데이터에만 의존하는 이전 작업들과 달리 대형 LM(Transformer Language Models)의 텍스트 임베딩을 활용합니다.
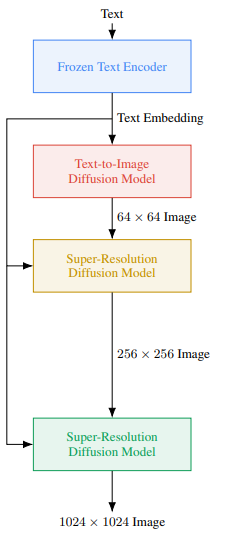
이때 Imagen은 텍스트 임베딩을 위한 고정된 T5-XXL 인코더와 64x64, 256x256, 1024x1024 확산 모델로 구성됩니다.

Classifier-free guidance 및 더 높은 충실도의 이미지를 생성하는 새로운 샘플링 기술 사용을 합니다.
Text-to-image 평가를 위한 구조화된 text prompt 모음인 DrawBench를 소개한다. 여기에는 희귀 단어가 포함된 prompt도 있으며 매우 그럴듯한 장면을 생성하는 능력, 창의력 등을 평가합니다.
Imagen
Pretrained text encoders
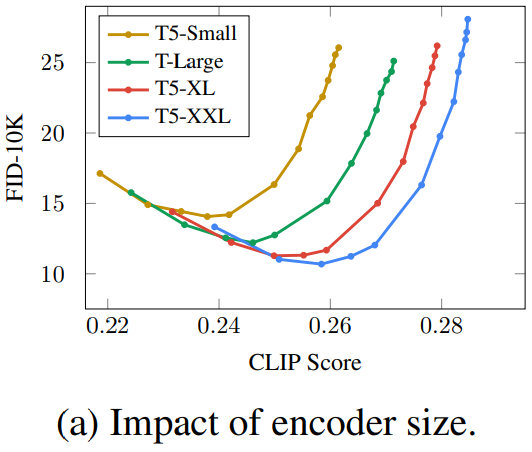
비교를 위해 BERT, T5, CLIP 사용합니다.여기서 연구진은 인코더 크기를 키우면 생성 품질이 향상된다는 분명한 사실을 발견을 하였습니다. T5-XXL 및 CLIP 인코더는 간단한 벤치마크에서는 비슷했지만 새로운 벤치마크 DrawBench에서는 T5-XXL이 분명한 우위를 가졌습니다.
Diffusion models and classifier-free guidance
여기서 확산 모델 간략한 설명합니다. (여기서 기호는 별로 안중요하고 x-prediction이 뭔지 아는것이 중요합니다.)
확산 모델 x̂θ는 zt(:= αtx + σtε)를 denosing 하도록 훈련됩니다.
( 각 확산 단계의 이미지 zt, x-prediction x̂t0 := x̂θ(zt,c) )
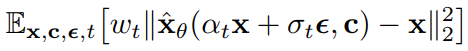
Text conditioning을 위해 Classifier-free Guidance 사용합니다.
ε-prediction εθ := (zt - αtx̂θ)/σt에 대해서는 아래와 같습니다.
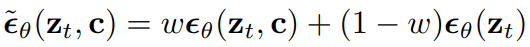
샘플링은 조정된 x-prediction (zt - σε̃θ)/αt 를 사용하여 수행됩니다.
Large guidance weight samplers
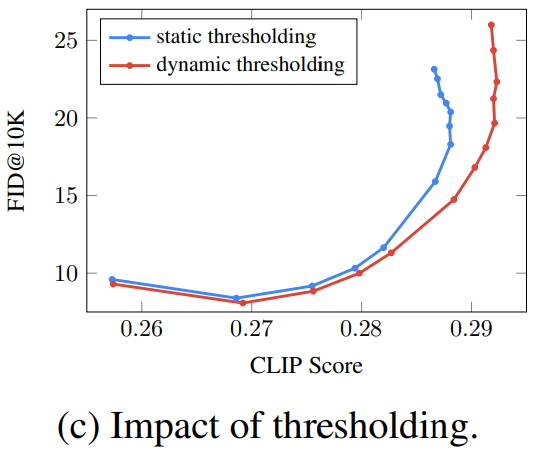
여기서 가이드의 가중치 w를 늘리면 채도가 높고 부자연스러운 이미지가 생성된다는 것을 발견이 되었고, 이는 높은 가중치로 인한 train-test 불일치에서 기인합니다. 특히 매우 높은 가중치의 이미지는 명백히 훈련 데이터의 범위에 있지 않습니다. (Classifier-free Guidance가 평균과 분산을 이동시킴).
또한 이러한 문제는 확산 단계에서 반복적으로 누적되면서 이 문제를 해결하기 위해서는 정적 임계값과 동적 임계값을 조사합니다.
Static thresholding
x-prediction을 [-1,1]로 클리핑한다. 하지만 여전히 과포화되고 덜 상세한 이미지가 생성됨.
Dynamic thresholding
특정 백분위수 절대 픽셀 값을 s로 하고 s>1 이면 임계값을 [-s,s]로 지정한 다음 s로 나눕니다.(e.g. 90% 지점의 픽셀 값이 3이면 [-3,3]으로 클리핑한 후 3을 나누어 [-1,1]로 바꿈)

Robust cascaded diffusion models
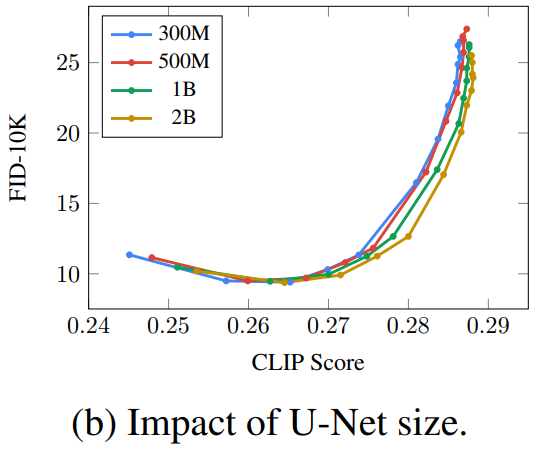
고해상도 이미지 생성을 위해 Cascaded Diffusion Models(CDM) 사용합니다.
CDM에서는 저해상도 모델의 augmentation으로 Gaussian noise를 사용하고 초해상도 모델에 noise level을 조건으로 넘기는데, 해당 논문에서는 첫 번째 초해상도 모델에서만 사용하지만 이 논문에서는 두 초해상도 모델 모두에서 사용합니다.

Neural network architecture
64x64의 기본 모델에서는 Improved DDPM의 U-Net의 베이스로 하고 확산 시간 단계 임베딩과 pooled text embedding을 조건으로 한다. 텍스트 조건화를 위한 cross-attention을 추가했습니다.
텍스트 조건화에 대해 다양한 방법을 시험하여 성능 향상에 상당한 도움이 되는 텍스트 임베딩을 위한 Layer Normalization과 풀링 레이어를 찾았습니다.
64 → 256 초해상도 모델의 경우 메모리 효율과 추론 속도 개선을 위해 수정된 Efficient U-Net 사용합니다.
- 저해상도에서 더 많은 잔차 블록
- Skip connection을 1/√2로 스케일링
- 다운샘플링과 업샘플링 블록 모두에 대해 컨볼루션과 크기 조정 순서를 반대로 함
256 → 1024 모델의 경우 속도를 위해 self attention을 제거합니다.
Evaluation Text-to-Image Models
DrawBench에는 11가지 범주의 200개의 prompt로 색상, 개체 수, 공간 관계, 장면의 텍스트 및 개체 간의 비정상적인 상호 작용을 충실하게 렌더링하는 기능과 같은 모델의 다양한 기능을 테스트하며 범주에는 길고 복잡한 텍스트 설명, 희귀 단어 및 철자가 틀린 prompt를 비롯한 복잡한 prompt가 포함됩니다.

Experiments
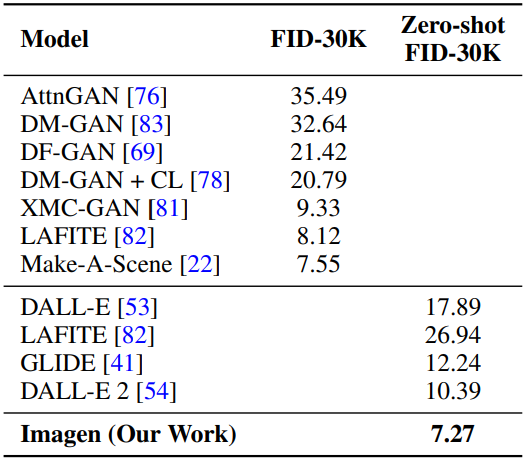
MS-COCO 256 × 256 FID-30K
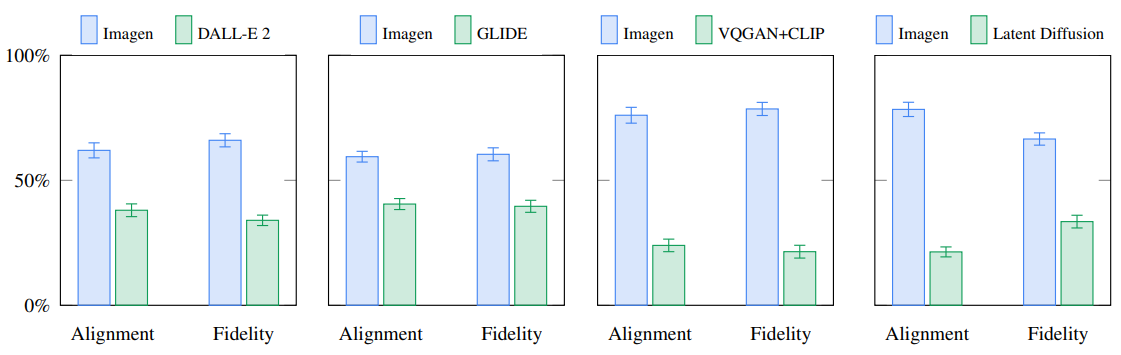
DrawBench로 생성된 이미지들을 인간이 평가합니다.
Ablation