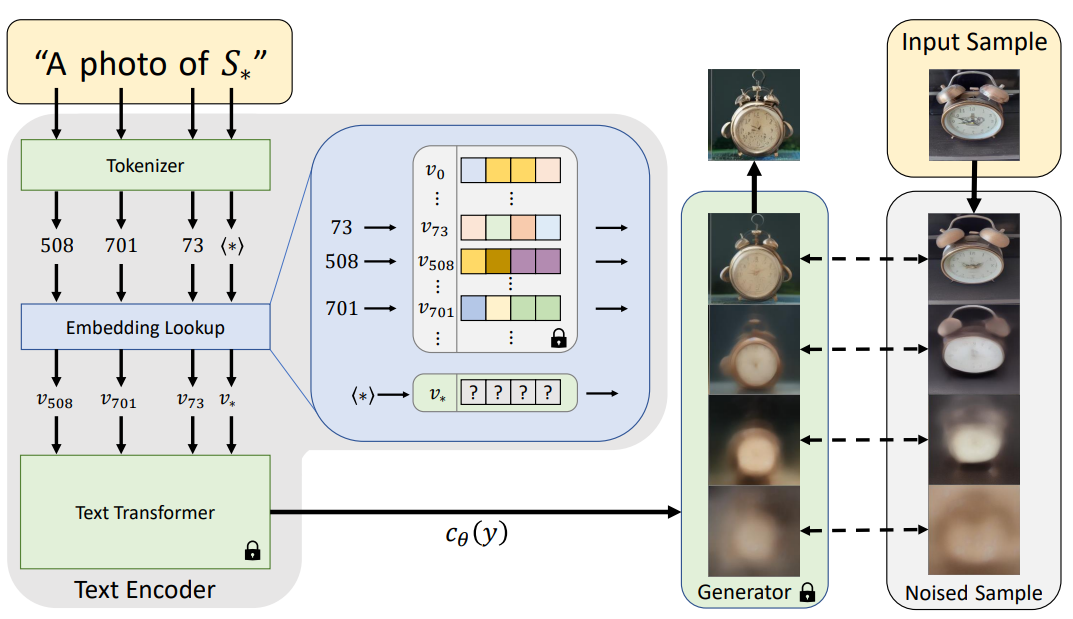
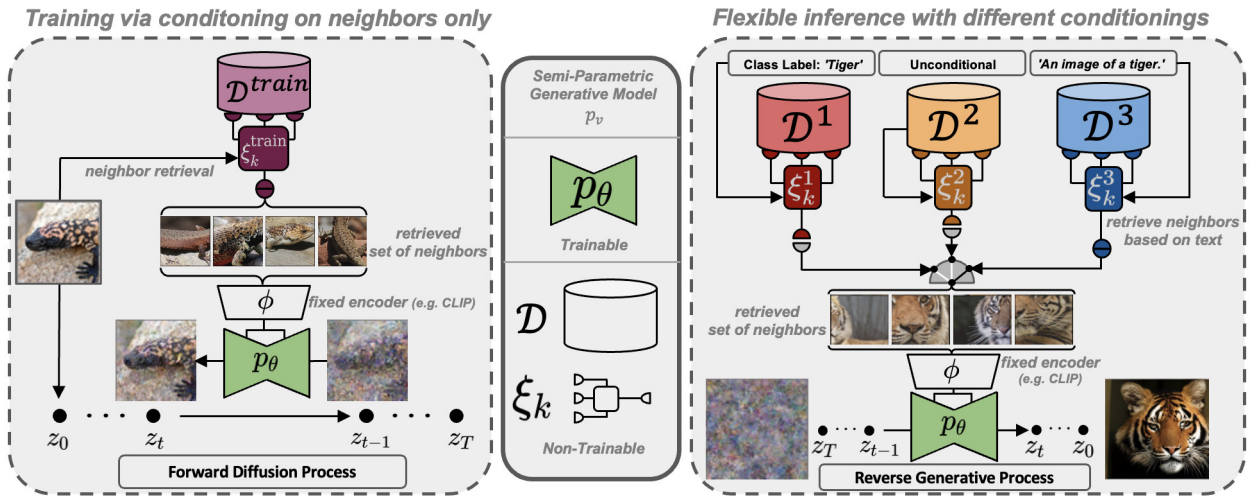
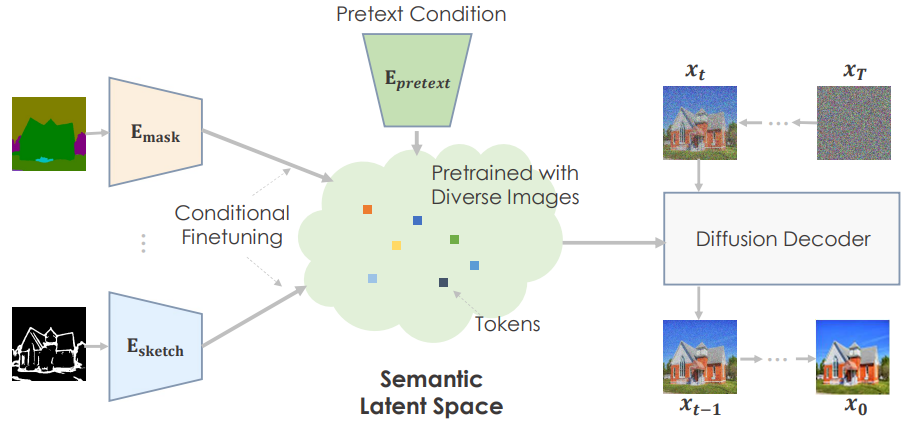
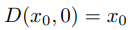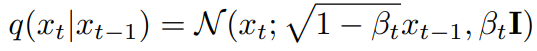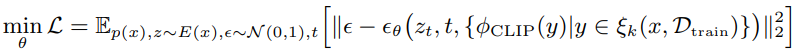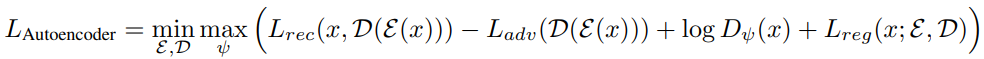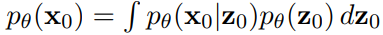Link 논문 링크 https://arxiv.org/abs/2208.09392v1 깃허브 링크 https://github.com/arpitbansal297/cold-diffusion-models Abstract 연구진들은 Diffusion Model의 생성적 동작이 이미지 저하의 선택에 크게 의존하지 않는다는 것을 관찰했으며 완전히 결정적인 저하(blur, masking 등)를 사용하는 경우에도 규칙을 쉽게 일반화하여 생성 모델을 만들 수 있습니다. 이러한 완전 결정론적 모델의 성공은 gradient Langevin dynamics 또는 변분 추론의 노이즈에 의존하는 확산 모델에 대한 의문을 제기하고 일반화된 확산 모델의 길을 열어줍니다. Introduction 본 논문에서는 Diffusion Model..