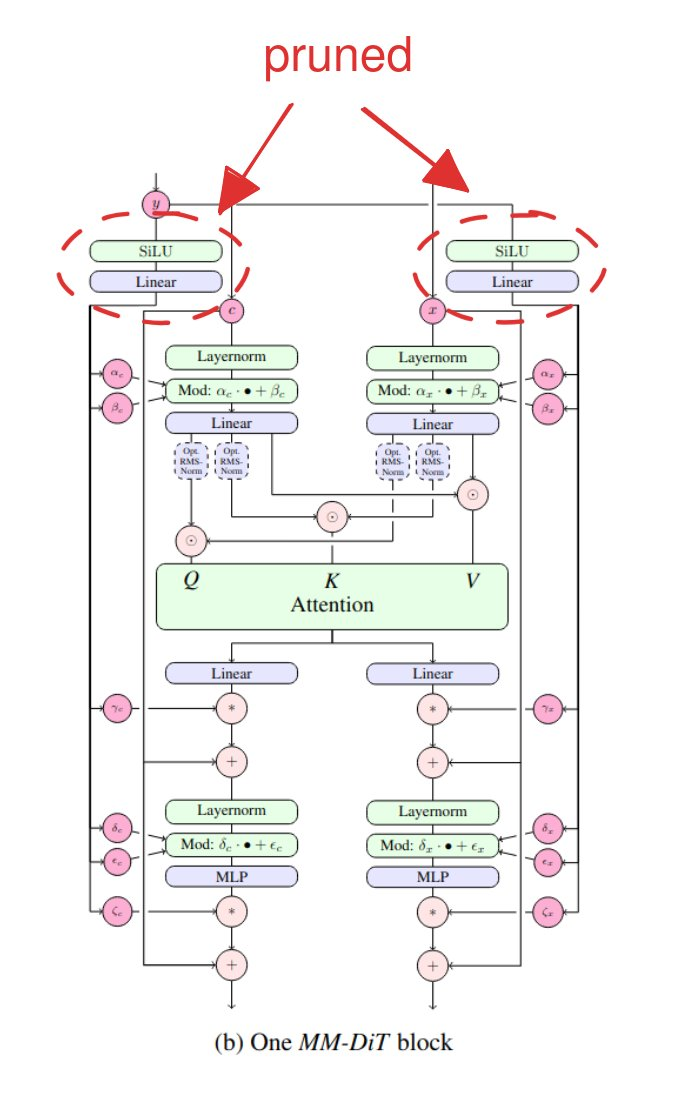
Chroma는 FLUX.1-schnell에서 파생된 8.9B(89억) 파라미터 모델로, 접근성과 자유, 혁신을 최우선으로 하는 강력한 오픈 소스 AI 모델입니다. Apache 2.0 라이선스로 출시되어 누구나 자유롭게 사용할 수 있으며, 수정 및 확장이 가능하고 기업의 제약 없이 활용할 수 있습니다.현재 오픈소스로 공개가 되어있고 학습 중인 Chroma는 방대한 데이터셋을 활용하여 생성형 AI의 한계를 확장하는 것을 목표로 하고 있다고 합니다. 이번 블로그에서는 Chroma 프로젝트의 목표, 기술적 혁신, 모델 구조, 그리고 오픈 소스 커뮤니티와 협력하는 방법을 자세히 살펴보겠습니다.Chroma의 목표Chroma는 2천만 개의 원본 샘플 중 5백만 개의 고품질 데이터를 엄선하여 학습되었습니다. 데이터셋에..