1. 서론
대규모 이미지 생성 모델인 Flux와 SDXL의 성능을 최적화하는 것은 실용적 응용에 있어 매우 중요합니다. 이 리서치글에서는 TorchAO와 PyTorch의 torch.compile() 기능을 활용하여 이러한 모델들의 추론 속도를 향상시키고 메모리 사용량을 줄이는 방법에 대해 살펴보겠습니다.
2. TorchAO를 이용한 양자화
2.1 기본 양자화 적용
Flux나 SDXL 모델에 TorchAO의 양자화를 적용하는 기본적인 방법은 다음과 같습니다:
from diffusers import FluxPipeline# 또는 StableDiffusionXLPipeline
from torchao.quantization import autoquant
import torch
pipeline = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16
).to("cuda")
pipeline.transformer = autoquant(pipeline.transformer, error_on_unseen=False)
2.2 양자화 기법 선택
TorchAO는 다양한 양자화 기법을 제공합니다. Flux와 SDXL에 적용 가능한 주요 기법들은 다음과 같습니다:
- int8 weight-only: 가중치만 8비트 정수로 양자화
- int8 dynamic: 동적으로 8비트 정수 양자화 수행
- fp8: 8비트 부동소수점 양자화 (Hopper 아키텍처 필요)
- fp8dqrow: 개선된 8비트 부동소수점 양자화
- autoquant: 자동으로 최적의 양자화 방식 선택
각 기법의 선택은 모델 크기, 요구되는 정확도, 사용 가능한 하드웨어에 따라 달라질 수 있습니다.
2.3 양자화 성능 비교
Flux.1-Dev 모델을 기준으로 한 벤치마크 결과:
- 기본 bfloat16: 6.431초 (H100 GPU)
- int8 weight-only: 약 27-53% 속도 향상
- fp8dqrow: 2.966초 (가장 빠른 성능, H100 GPU)
SDXL의 경우도 유사한 성능 향상을 기대할 수 있으며, 특히 큰 배치 크기에서 더 큰 이점을 얻을 수 있습니다.
3. torch.compile() 사용 이유

위에 내용은 Flux 아키텍쳐의 모습인데 이 중에서 확인해야 될 부분은 text prompt에서 들어간 후 LayerNorm → Modulation → RMSNorm → RoPE + Attn + Split 부분의 최적화가 필수 입니다.
torch.compile()을 사용해야 하는 주된 이유는 모델의 성능을 크게 향상시킬 수 있기 때문입니다. 아래에 제공된 그래프에서 볼 수 있듯이, torch_compile (녹색 선)은 일반 torch (점선) 대비 훨씬 높은 처리량(GB/s)을 보여줍니다. 특히 긴 시퀀스 길이에서도 안정적으로 높은 성능을 유지합니다. 이는 Flux와 같은 대규모 언어 모델의 추론 속도를 크게 개선할 수 있음을 의미합니다.
아래의 성능 그래프는 RTX 3090Ti을 기반으로 테스트를 진행한 데이터를 가져왔습니다.
Q, K, V (Query, Key, Value)
- 이들은 Transformer 아키텍처의 핵심 구성 요소입니다.
- Flux 모델 다이어그램에서 "Multi-Head Attention" 블록 내부에서 처리됩니다.
- Query: 현재 위치의 토큰이 다른 토큰들과 얼마나 관련이 있는지 질문합니다.
- Key: 다른 토큰들의 "정체성"을 나타냅니다.
- Value: 실제 정보 내용을 담고 있습니다.
- 주의: Q, K, V는 입력을 서로 다른 선형 변환을 통해 얻어집니다.

LayerNorm + Modulation
- 그래프의 제목에서 언급된 이 기술은 Flux 모델의 중요한 특징입니다.
- LayerNorm: 각 레이어의 출력을 정규화하여 학습을 안정화시킵니다.
- Modulation: 정규화된 출력에 추가적인 스케일링과 시프팅을 적용하여 모델의 표현력을 향상시킵니다.
- Flux 다이어그램에서 "Add & LN" 블록으로 표시되어 있을 가능성이 높습니다.

RMSNorm (Root Mean Square Normalization)
- LayerNorm의 변형으로, 계산 효율성이 더 높습니다.
- 평균을 빼지 않고 오직 제곱근 평균으로만 정규화합니다.
- Flux 모델에서 사용될 수 있으며, 다이어그램의 정규화 단계에서 구현될 수 있습니다.
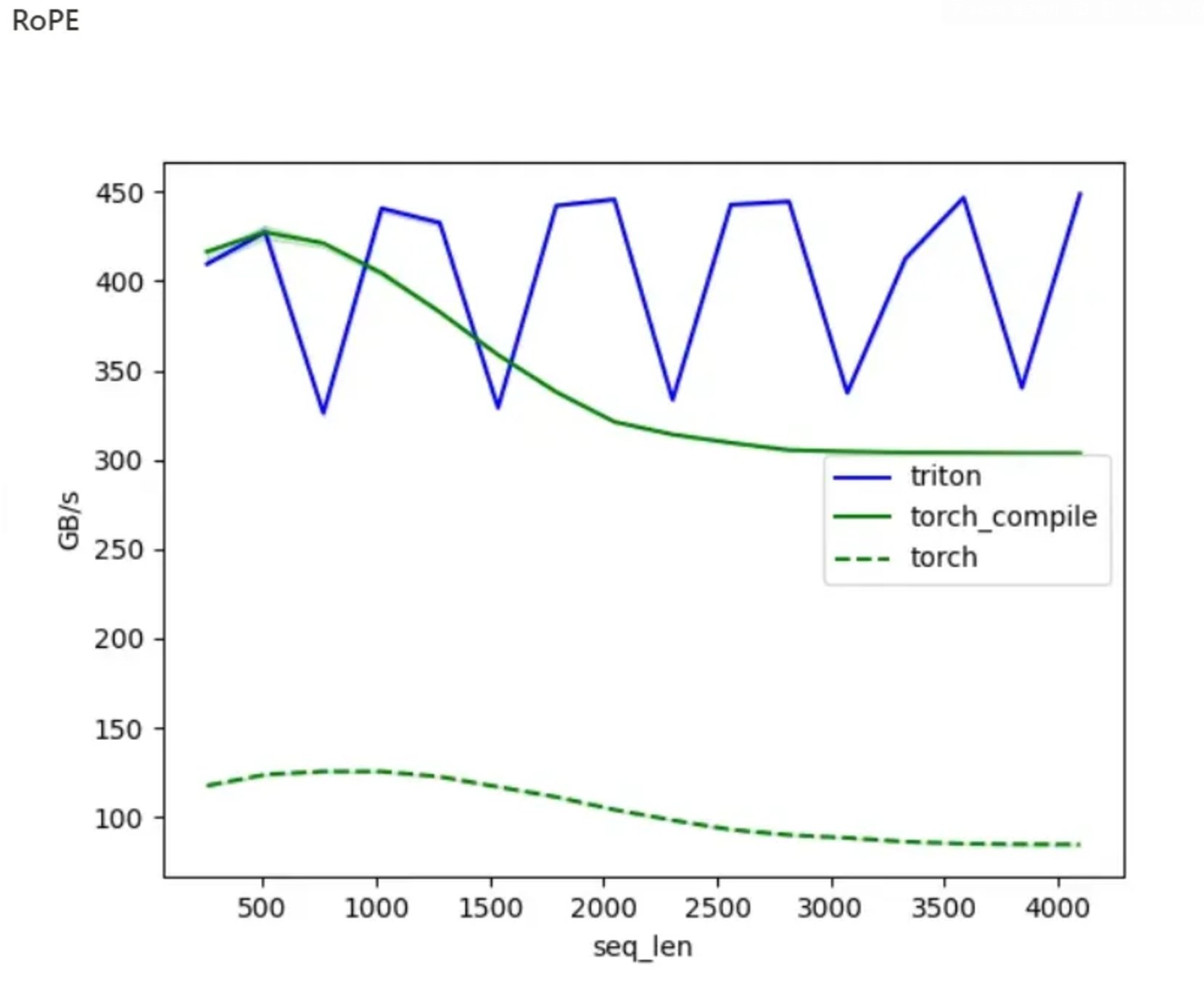
RoPE (Rotary Position Embedding)
- 위치 정보를 임베딩하는 효과적인 방법입니다.
- 토큰의 상대적 위치 관계를 보존하면서 시퀀스 길이에 대한 일반화 능력을 향상시킵니다.
- Flux 다이어그램에서 명시적으로 보이지 않지만, "Multi-Head Attention" 블록 내부나 그 주변에서 적용될 가능성이 높습니다.
여기서 추가적으로 torch.compile()을 사용을 하면 성능이 향상이 되는지는 아래와 같습니다.
- torch.compile()은 모델의 계산 그래프를 분석하고 최적화합니다. 이 과정에서 불필요한 연산을 제거하고, 여러 연산을 더 효율적인 단일 연산으로 융합합니다.
- 특정 GPU 아키텍처에 맞춰 코드를 최적화합니다. 예를 들어, 텐서 코어나 특정 GPU의 메모리 계층 구조를 최대한 활용하는 방식으로 연산을 재구성합니다.
- 데이터 이동을 최소화하고 캐시 사용을 최적화하여 메모리 대역폭 활용을 개선합니다.
- 실행 시간에 모델을 컴파일하여 특정 입력 크기와 데이터 유형에 최적화된 코드를 생성합니다.
- 여러 개의 작은 연산을 하나의 큰 연산으로 융합하여 오버헤드를 줄입니다.
- GPU의 병렬 처리 능력을 최대한 활용할 수 있도록 연산을 재구성합니다.
4. torch.compile() 활용
4.1 기본 적용 방법
torch.compile()을 Flux나 SDXL 모델에 적용하는 방법:
pipeline.transformer.to(memory_format=torch.channels_last)
pipeline.transformer = torch.compile(
pipeline.transformer, mode="max-autotune", fullgraph=True
)
4.2 컴파일 최적화 팁
- 그래프 브레이크 방지: 모델 내 연산 그래프가 끊기지 않도록 주의
- 프로파일링 활용: torch.profiler.profile()을 사용하여 성능 병목 지점 파악
- 컴파일 결과 캐싱: ENABLE_AOT_AUTOGRAD_CACHE 플래그 사용으로 컴파일 시간 단축
5. 메모리 최적화 기법
5.1 CPU 오프로딩
pipeline.enable_model_cpu_offload()
이 방법으로 GPU 메모리 사용량을 크게 줄일 수 있습니다.
5.2 VAE 타일링
pipeline.vae.enable_tiling()
VAE 타일링을 통해 큰 해상도의 이미지 생성 시 메모리 사용량을 줄일 수 있습니다.
5.3 순차적 CPU 오프로딩
pipeline.enable_sequential_cpu_offload()
더 적극적인 메모리 절약이 필요할 때 사용할 수 있지만, 추론 시간이 늘어날 수 있습니다.
6. 고급 최적화 기법
6.1 Autoquant 활용
Autoquant를 사용하여 자동으로 최적의 양자화 계획을 수립하고 재사용할 수 있습니다:
from torchao.quantization.autoquant import AUTOQUANT_CACHE
import pickle
# 양자화 계획 저장
with open("quantization-cache.pkl", "wb") as f:
pickle.dump(AUTOQUANT_CACHE)
# 양자화 계획 로드 및 사용
with open("quantization-cache.pkl", "rb") as f:
AUTOQUANT_CACHE.update(pickle.load(f))
6.2 Autotuning
int8 동적 양자화와 가중치 양자화를 위한 커널 최적화:
TORCHAO_AUTOTUNER_ENABLE=1 TORCHAO_AUTOTUNER_DATA_PATH=my_data.pkl python my_script.py
이 과정은 시간이 많이 소요될 수 있지만, 최적의 커널 구성을 찾아 성능을 향상시킬 수 있습니다.
7. 주의사항 및 팁
- 하드웨어 의존성: 최적화 효과는 사용하는 GPU에 따라 다를 수 있습니다.
- 모델 크기 영향: 큰 모델일수록 양자화의 효과가 더 크게 나타납니다.
- 작은 행렬 곱: 작은 크기의 행렬 곱에서는 양자화가 오히려 성능을 저하시킬 수 있습니다.
- 컴파일 시간: 첫 컴파일은 시간이 오래 걸릴 수 있으므로, 결과를 캐시하여 재사용하는 것이 중요합니다.
8. 결론
Flux와 SDXL 모델의 성능을 최적화하기 위해 TorchAO의 양자화 기법과 PyTorch의 torch.compile()을 활용할 수 있습니다. 적절한 양자화 방법 선택, 메모리 최적화 기법 적용, 그리고 컴파일 최적화를 통해 추론 속도를 크게 향상시키고 메모리 사용량을 줄일 수 있습니다.
하지만 최적화 과정에서 모델의 정확도와 생성 품질을 지속적으로 모니터링해야 하며, 특정 하드웨어와 모델 구조에 따라 최적의 설정이 달라질 수 있음을 유의해야 합니다. 따라서 실제 적용 시에는 다양한 설정을 실험하고 벤치마크하여 최적의 구성을 찾는 것이 중요합니다.
'머신러닝 & 딥러닝 > 딥러닝' 카테고리의 다른 글
| Stable Diffusion 3.5 Medium 모델 학습 최적화 가이드 (0) | 2024.11.23 |
|---|---|
| Flux perfermence improved by Flash attention3 + Triton (2) | 2024.11.22 |
| Langchain 문서(Simple Start) (0) | 2024.11.19 |
| Flux.1-dev 모델 구조와 작동 원리 (0) | 2024.11.18 |
| [AI 기초 다지기] Kolmogorov Complexity and Algorithmic Randomness (0) | 2024.11.17 |