Link
Abstract
아직 Text-to-image 모델이 어떻게 이미지를 생성, 구성하는지 불분명합니다. 본 논문에서는 창조적 자유를 허용하는 간단한 접근 방식을 제시한다. 3~5개의 이미지만을 이용하여 임베딩 공간에서 새로운 "words"를 통해 표현하는 방법을 배웁니다.
Introdution
새로운 개념을 대규모 모델에 도입하는 것은 어렵습니다. 재교육에는 비용이 많이 들고, fine tuning은 기존의 것을 망각할 위험이 있습니다.
사전 훈련된 text-to-image 모델의 텍스트 임베딩 공간에서 새로운 word를 찾아 이러한 문제를 극복할 것을 제안합니다. 새로운 pseudo-word를 S*로 표시하고 생성모델을 변경하지 않은 채로 S*를 다른 일반적인 words처럼 처리합니다.
S*을 정의하는 과정을 “Textual Inversion”이라고 하고 다양한 반전 방법을 조사합니다.
Method
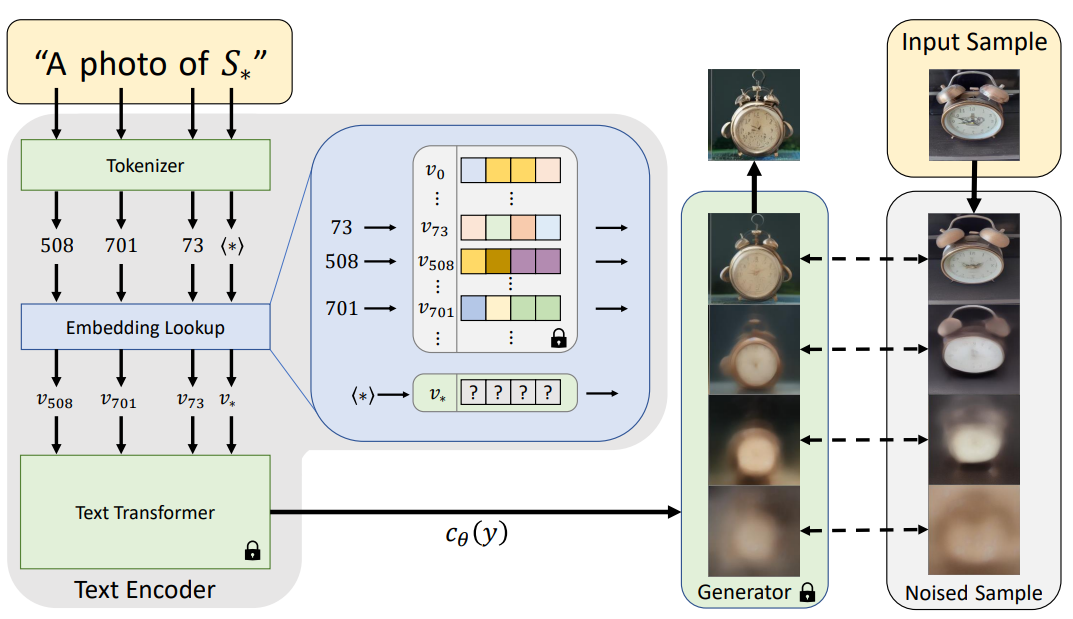
일반적인 text-to-image 모델에서는 단어 임베딩 단계(주로 CLIP)에서 표현에 대한 후보를 검색합니다. 이러한 방법은 이미지에 대한 깊은 시각적 이해를 필요로 하지 않기 때문에 본 논문에서는 GAN 반전에서 영감을 받은 시각적 재구성 목표를 통해 pseudo-words를 찾습니다.
Latent Diffusion Models
Autoencoder 구조와 cross-attention을 도입한 Latent Diffusion Models (LDMs)를 생성 모델로 사용합니다.
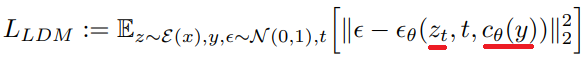
Text embeddings
BERT와 같은 일반적인 텍스트 인코더 모델은 아래 그림과 같이 토큰화와 고유 벡터에 임베딩하는 과정을 거칩니다. 이 임베딩 공간을 반전 대상으로 선택하고 S*와 관련된 벡터를 v*로 교체합니다.

Textual inversion
새로운 임베딩을 찾기 위해 3~5개의 적은 이미지를 사용하고 이미지에 대해 LDM 손실을 직접 최적화하여 v*를 찾습니다.
생성을 조절하기 위해 CLIP ImageNet template에서 파생된 중립적 context text를 무작위로 샘플링합니다.(e.g. “A photo of S∗”, “A rendition of S∗”)

여기서 생성 모델 가중치는 고정을 진행하고 텍스트 인코더만 훈련됩니다.
Qualitative comparisons and applications
Image variations
이미지 재구성 성능을 비교합니다. 본 논문의 모델이 텍스트로 표현할 수 없는 세부적인 시각적 특징을 잘 보존하는 것을 볼 수 있습니다.

Text-guided synthesis
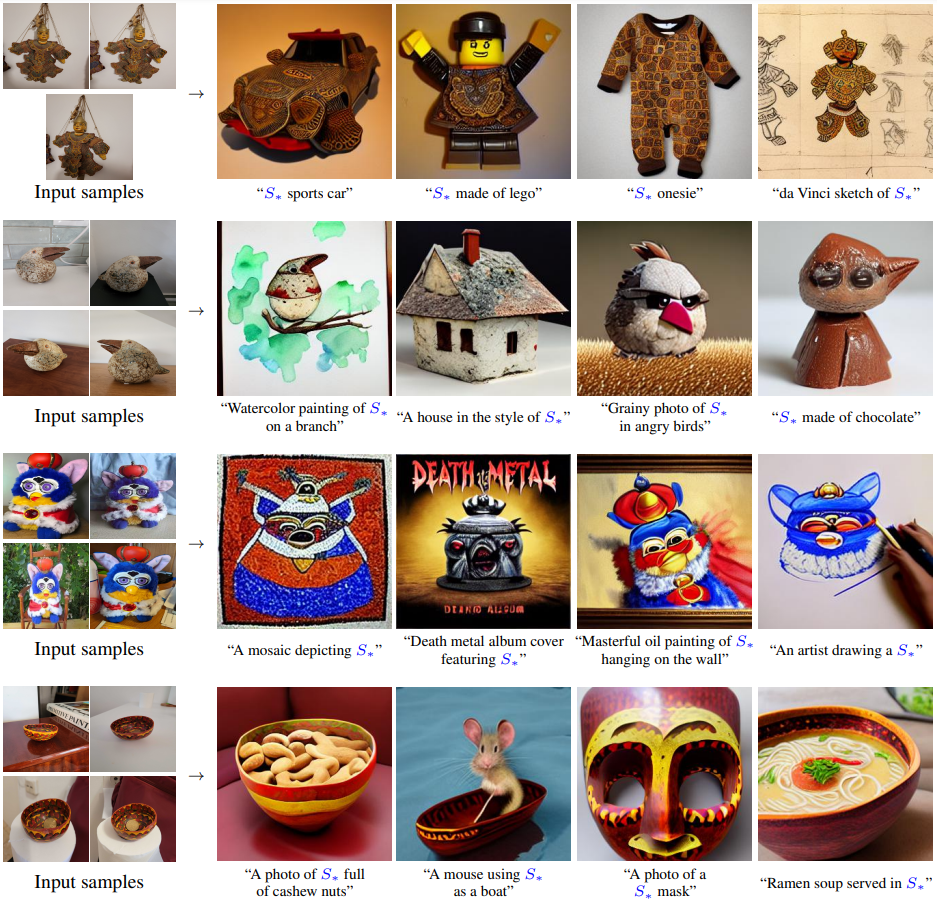
밑에 사진을 보면 다른 모델과 비교해도 시각적 특징이 잘 보존 되있다라는 것을 확인할 수 있습니다.

Style transfer
훈련 단계에서 context text를 "A painting in the style of S*"와 같은 형식으로 대체하려 스타일 전송 작업 또한 가능합니다.

Concept compositions
동시에 여러 개의 새로운 words를 추론할 수 있지만 새로운 words 간의 관계에서는 어려움을 겪습니다.

Bias reduction
LDM을 기반으로 하는 다른 모델에도 적용할 수 있는데, 여기서는 Blended Latent Diffusion을 예시로 했습니다.
