Link
논문 링크 https://arxiv.org/abs/2204.11824
깃허브 링크 https://github.com/lucidrains/retrieval-augmented-ddpm
Abstract
자연어 처리에서 RAG에 영감을 받아서 검색 기반 접근 방식으로 Diffusion Model을 보안하고 외부 데이터베이스 형태의 명시적 메모리를 도입하는 것을 제안합니다. 본 논문의 확산 모델은 CLIP을 통해 각 훈련 인스턴스의 이웃에서 검색된 유사한 시각적 특징으로 훈련됩니다. 또한 적은 계산 및 메모리 오버헤드를 발생시키고 구현하기 쉽습니다.
Introduction
Diffusion model을 사용한 retrieval-augmented 생성 모델링을 위한 간단한 프레임워크를 제시합니다.
CLIP의 잠재 공간을 검색하고 조건화하여 계산 오버헤드가 거의 없는 가장 가까운 이웃 표현을 통합하는 효율적인 방법을 제시합니다.
검색이 빠르고 CLIP 임베딩에 대한 컨디셔닝에는 추가 저장 공간이 거의 필요하지 않니다.
FID 및 다양성 측면에서 최신 확산 모델을 능가하는 동시에 훈련 가능한 매개변수가 적고 CLIP의 image-text feature space는 이미지에 대해서만 교육을 받았음에도 불구하고 text-image 또는 클래스 조건부 합성과 같은 다양한 조건부 응용 프로그램을 허용합니다.
마지막으로, 테스트 도중에 검색 데이터베이스를 변경하는 것이 합성 프로세스 제어에 추가적인 유연성을 제공하고 분류기 없는 확산 지침과 같은 기존 샘플링 기술과 결합될 수 있음을 보여줍니다.
Image Synthesis with Retrieval-Augmented Diffusion Models
본 논문의 작업에서는 데이터 포인트를 모델의 명시적 부분으로 간주합니다. 이 접근 방식은 신견망의 가중치뿐만 아니라, 훈련 데이터로부터 query가 주어지면 적정한 데이터 표현을 검색하는 데이터 표현 집합과 검색 함수에 의해 매개 변수화됩니다.

Retrieval-Enhanced Generative Models of Images
훈련 가능한 모델 구성 요소와 훈련 불가능한 모델 구성 요소 튜플을 도입하여 반모수(semiparametric) 생성 모델 pν(x)를 정의합니다.
ν = {θ, D, ξk}, D는 yi의 데이터베이스, ξk는 D에서 k개 구성요소를 가진 하위 집합을 얻기 위한 샘플링 전략, θ는 피라미터이다. (훈련 중에는 decoding head라고 하는 θ만 학습됨.)
ξk(x, D)는 유익한 시각적 표현을 모델에 제공하고 θ에서 장면을 구성합니다.
(e.g. ξk(x, D) = 거리 함수 d(x, ·)로 측정된 k-최근접 이웃 집합 반환 함수)
검색 정보 조건화를 통해 반모수 생성 모델을 다음과 같이 정의 :
그러나 검색된 이미지는 많은 모호성과 계산 및 저장 비용이 필요하기 때문에 사전 훈련 이미지 인코더 φ를 사용하여 D의 모든 예를 저 차원 매니폴드(d=512)에 투영됩니다.
Semi-Parametric Diffusion Models
훈련에는 pν(x)로 근사하려는 분포 p(x)를 가진 데이터셋 X가 제공되며 ξk는 쿼리 예제 x에 대해 CLIP feature 공간에서 코사인 유사도 d(x,y)로 k-최근접 이웃을 검색합니다.
Decoding head로 latent diffusion model(LDM) 사용합니다. 이론상 모든 생성 모델을 반모수 모델로 전환할 수 있다. CLIP을 사용한 이유는 잠재 공간이 매우 작고 text-iamge 합성에 유용하기 때문입니다.
RDM의 최종 목표 :
(기댓값은 훈련 예제에 대한 경험적 평균으로 근사합니다. θ에 φCLIP(y)를 공급하기 위해 LDM에서 제안한 cross-attention conditioning mechanism 사용됩니다.)
Inference for Retrieval-Augmented Diffusion Models
Conditional Synthesis without Conditional Training
D와 ξk의 상호 교환성으로 검색 방법을 바꾸거나 추가적인 조건화, 또는 검색을 건너뛰고 φCLIP(y)를 직접 제공하는 방법 등으로 추가 조건부 정보를 통해 보다 세분화된 제어를 제공할 수 있습니다.
For unconditional generative modeling
D에서 x̃를 샘플링하고, ξktrain = ξktest(훈련과 테스트를 같은 D에서 실행) 일 때 ξktest(x̃, D)를 얻으면 decoding head를 통해 샘플 추출 모델로 사용할 수 있습니다. 그러나 하나의 검색 집합으로만 샘플을 생성하면 자연의 다중모드가 아닌 단일모드 분포에서 생성돼 단순한 이미지만 나옵니다. 따라서 새로운 proposal distribution pD(x̃)를 제안합니다.

위 정의는 훈련 데이터 세트 X를 모델링하는 데 유용한 데이터베이스 D의 인스턴스를 계산한다. 새로운 분포는 X와 D에만 의존하므로 미리 계산할 수 있다. 다음과 같이 주어진 pD(x̃)에서 샘플을 얻을 수 있습니다.
Trading Quality for Diversity
Top-K Sampling과 유사하게 가장 가능성 있는 예제 집합 D(m) (m ∈ (0, 1])으로 분포를 자릅니다.
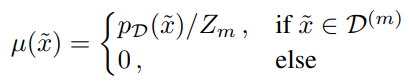
이를 proposal distribution으로 사용하여 품질을 절충하고 다양성을 확보할 수 있습니다.

다양성-품질 trade off에서 추가적인 유연성을 위해 Classifier-free diffusion과 같은 샘플링 기술을 사용할 수도 있습니다.
Experiments
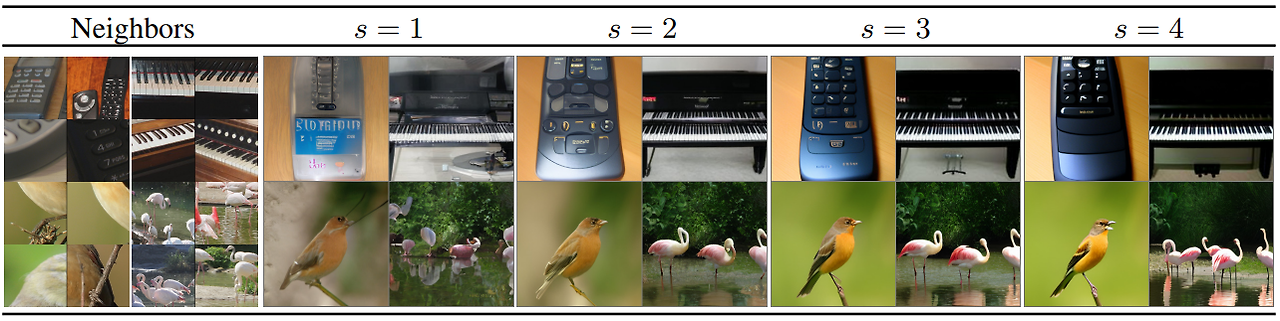
Unconditional RDM 샘플 (NN = 직접 최근접 이웃)

Class-conditional generation on ImageNet

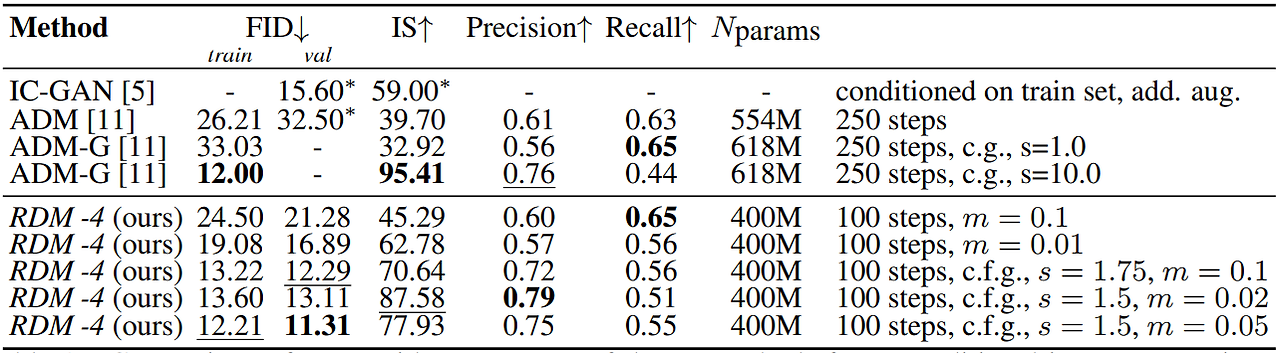
Classifier-free diffusion을 이용한 품질 조절