링크
Abstract
VQ-Diffusion에서 때때로 낮은 품질의 샘플이나 약한 상관관계의 이미지를 생성했는데, 주요한 원인 샘플링 전략 때문임을 발견하였고 주 가지 중요한 기술을 제안합니다.
- 이산 확산 모델에 대한 classifier-free guidence를 탐구하고 보다 일반적인 방법을 제안
- VQ-Diffusion의 joint distribution 문제를 완하하기 위한 푸론을 제안
Introduction
VQ-Diffusion의 주용 장점으로 각 이산 토큰에 대한 확률을 추정이 가능하여 상대적으로 적은 추론 단계로 고품질 이미지가 생성이 가능합니다. 이를 바탕으로 VQ-Diffusion을 개선하기 위한 몇 가지 기술을 소개합니다.
Discrete classifier-free guidance
조건부 이미지 생성의 경우 보통 diffusion 모델은 사전 확률 p(x|y)를 최대화하여 사후 확률 p(y|x)의 제약 조건을 만족한다고 가정합니다.
그러나 연구진들의 사후 확률을 무시할 수 없다라는 것을 발견하였습니다. 이것을 사후 문제로 명명하며, 이 문제를 해결 하기 위해 사전과 사후관계를 동시에 고려 할 것을 제안합니다. Classifier-free guidance의 개선과 사후 제약으로 크게 진전된 이미지를 생성할 수 있습니다.
High-quality inference strategy
각 노이즈 제거 단계에서 각 토큰들은 독립적으로 동시에 샘플링되기 때문에 종속성을 무시될 수가 있으며, 이것을 공동 분포 문제(joint distribution issue)라고 명명합니다.
이 문제를 완화하기 위해 두 가지 핵심 설계를 기반으로 하는 추론 정략을 도입합니다.
- 토큰이 많을수록 공통 분모로 인해 더 많은 어려움을 겪습니다. 이를 위해서 샘플링되는 토큰 수를 줄입니다.
- 신뢰도가 높은 토큰이 더 정확한 경향이 있다라는 것을 발견하였고 신뢰도가 높은 토큰에 purity prior를 토입하니다.
Method
Discrete Classifier-free Guidance
조건부 이미지 생성 작업의 경우 손상된 입력과 조건 정보를 통해 이미지 복구를 진행하는데, 손상된 입력이 조건 정보보다 훨씬 더 많은 정보를 갖고 있시 때문에 조건이 무시될 수 있습니다. 실제로도 VA-Diffusion에서 입력 텍스트와의 상관관계의 케이스를 발견하였습니다.
직접적인 해결책으로 사전 확률과 사후 확률을 동시에 최적화하는 것입니다.

무조건(unconditional) 이미지 로직 p(X)를 예특하기 위해 classifier-free guidance에서의 조건을 null을 입력하지만 이 논문에서는 학습 가능한 벡터를 사용하는 것이 성능이 더 좋다라고 합니다.
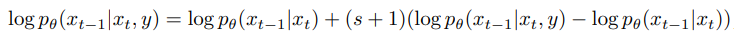
연속 도메인에서의 classifier-free guidance와 사후 확률 제약의 차이점:
- VQ-Diffusion은 재매개변수화를 이용하여 노이즈가 없는 p(x | y)를 예측하기 위해서 노이즈가 없는 상태에서 위에서의 argmax 등식을 사용할 수가 있고 빠른 추론, 고품질 추론과 같은 다른 기술에도 호환이 가능합니다.
- 연속적인 환경에서 diffusion model은 확률분포를 직접 예측하지는 않지만, 이산 확산 모델에서는 직접 추정하빈다.
- Null 대신 학습 가능한 벡터를 사용하였을 때 성능이 더웃 향상이 되었습니다.
High-quality Inference Strategy
Fewer tokens sampling
예를 들어 t-1 단계에서 t 단계로의 순방향 과정에서 20개의 마스크가 추가되었다고 가정합니다. 하지만 역방향에서 20개를 한번에 샘플링하면 공동 분포 문제가 생깁니다. 그래서 이 20개를 5개씩 총 4단계로 나누어서 샘플링을 하자고 제시합니다.
우리는 이미 순방향 과정에서 마스킹될 확률 Yt를 알고 있으니 샘플링 전에 단계를 얼마나 나눌지 정할 수 있습니다.
마스크를 1개씩 복구하면 AR(자동회기) 방식과 추론 속도가 같게 됩니다. 다만, diffusion 모델은 토큰들을 왼쪽 위로부터 순서 대로 추론함으로써 생기는 편향이 생기지 않기 때문에 다릅니다.
Purity prior sampling
모든 토큰은 위치 독립적이므로, 모든 위치에서 [MASK]가 될 확률은 같습니다.
하지만 위치에 따라 신뢰도가 다르면, purity가 높은 위치는 신뢰도도 높았다고 합니다.
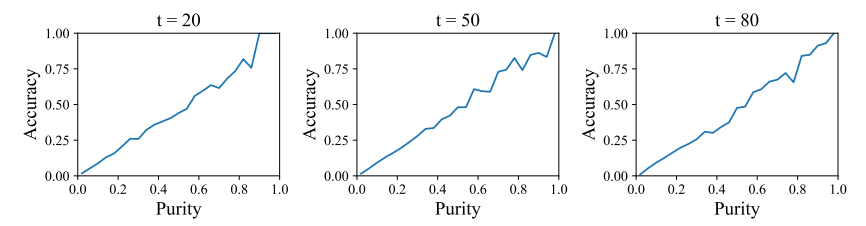
따라서 랜텀 샘플링 대신 purity에 의존하여 importance sampling을 수행합니다.

일단 역확산 과정에서 일관겅이 높은 자리의 마스크를 우선적으로 복구하는 것입니다.
또한 purity가 높은 위치의 첨도를 높이기 위해 softmax로 확률을 조정합니다.
