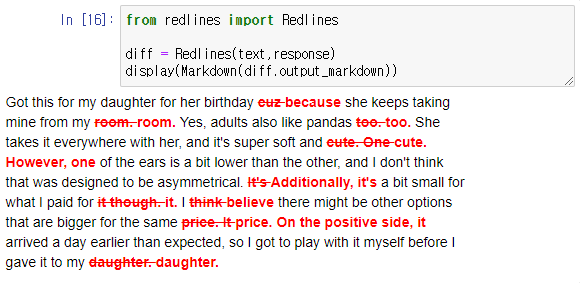
추론 이번 강의에서는 추론에 관한 것에 대해 이야기를 할 예정입니다. 모델이 텍스트를 입력으로 받아서 어떤 종류의 분석을 수행하는 이런 작업을 생각해봅니다. 이것은 라벨 추출, 이름 추출이 될 수 있고, 텍스트의 감정을 이해하는 것과 같은 것입니다. 감정을 추출하려면, 긍정적인지 부정적인지, 텍스트의 일부를, 전통적인 머신러닝 작업 흐름에서는 라벨 데이터 세트를 수집하고, 훈련시키고 모델을 배포하는 방법을 찾아야 하며 클라우드에서 추론을 해야 합니다. 그리고 감정 분석이나 이름 추출 등 각각의 작업에 대해서도, 별도의 모델을 훈련시키고 배포해야 합니다. 큰 언어 모델의 좋은 점 중 하나는 이러한 많은 작업들에 대해, 단순히 프롬프트를 작성하면 거의 즉시 결과를 생성하기 시작한다는 것입니다. lamp_re..