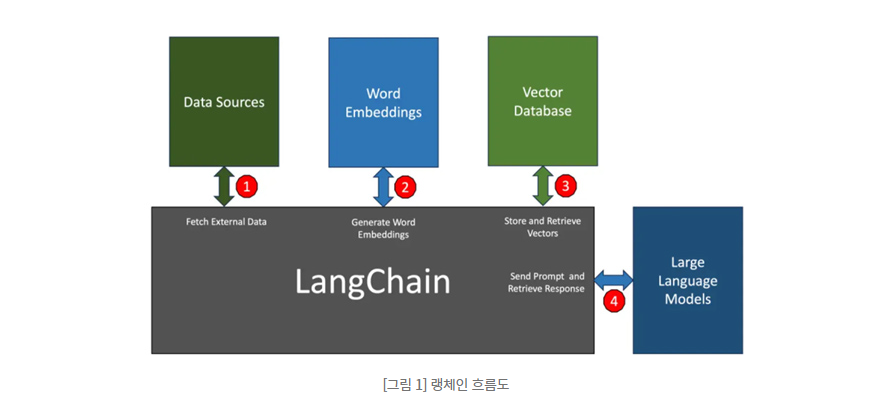
LangChain이란? 최근 다양한 기업들이 LLM 서비스를 어플리케이션과 통합을 하여 사용하는 추세입니다. 이러한 과정을 편리하게 하기 위하여 랭체인(LangChain)은 노출하여 대규모 언어 모델과 애플리케이션의 통합을 간소화하는 SDK입니다. 여기서 중요한 점은 오픈AI와 같은 공급업체가 제공하는 모델 API를 사용하든, 오픈소스 모델을 앱에 사용하든 LLM 기반 애플리케이션을 구축하기 위해서는 단순히 프롬프트를 보내는 것 뿐만 아니라 다양한 작업들이 존재합니다. 예를 들어, 매개변수 조정부터 프롬프트 보강, 응답 조정, LLM은 상태를 저장하지 않으므로 대화의 이전 메시지를 기억하지 못하기 때문에 맥락 정보가 새로운 대화에서 컨텍스트를 다시 가져오기 위해 영구적인 데이터 베이스를 사용해야 할수도 ..