Link
Abstract
Diffusion models이 이미지 샘플 품질보다 우수하다는 것을 보여주면서 분류기의 gradient를 활용한 조건부 이미지 합성으로 다양성을 절충하여 샘플 품질을 더욱 개선하는 방법을 제안합니다.
Introduction
GAN은 여전히 개선의 여지가 많으면서 다양한 도메인에 적용하는 것은 어려움이 있습니다.
Diffusion models은 likelihood 기반 모델이면서 분포 범위, 고정된 훈련 목표 및 쉬운 확장성과 같은 바람직한 속성을 제공하면서 고품질 이미지를 생성하는 것이 가능합니다.
다만 Diffusion models은 ImageNet과 같은 어려운 데이터셋에서 여전히 GAN에 뒤처지는데, 본 논문에서는 다음과 같은 요인에 비롯된다고 가정합니다.
- GAN은 최근까지도 많츤 연구가 진행이 되었고 개선이 되었습니다.
- GAN은 충실도를 위해 다양성을 절충해 고품질 샘플이 생성이 가능하다.
먼저 확산 모델에 위와 같은 이점을 제공하는 것을 목표로 하며 섹션 2에서는 이전 연구들, 섹션 3에서는 간단한 아키텍처 개선사항, 섹션 4에서는 분류기의 gradient를 사용하는 방법을 설명합니다.
Background
들어가기 전에 간단히 Diffusion Models에 대해 설명을 진행합니다.
Diffusion Models에서 Model은 다음 이미지를 추정하는 것이 아니라 VAE와 같이 매개변수화를 이용하여 랜덤 샘플링된 가우스 노이즈를 추정하는 것입니다.
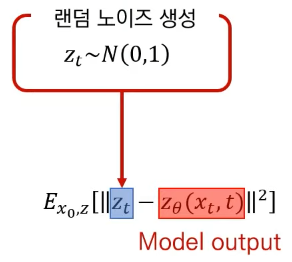
추정된 노이즈를 제거하여 다음 이미지를 추정합니다.
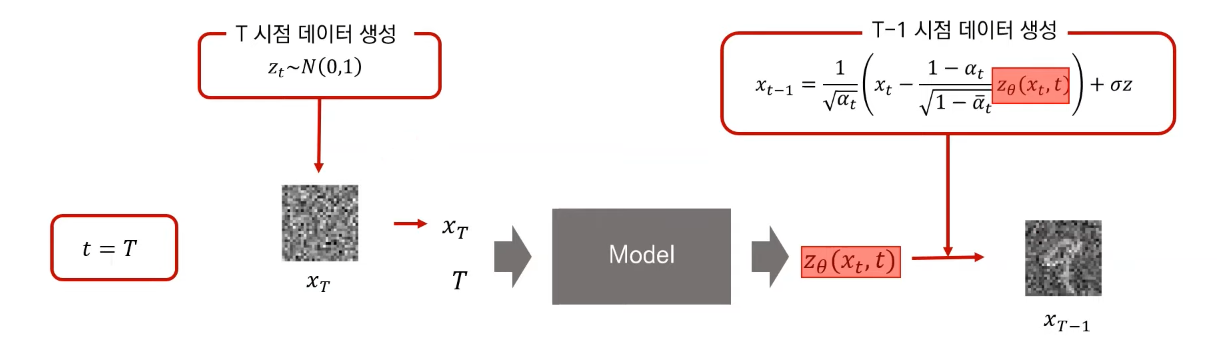
아래는 간단한 코드 예시입니다.
"""
x = noised images
t = timestep
"""
predicted_noise = model(x, t, training=False)
alpha_t = extract(alpha, t)
alpha_hat_t = extract(alpha_hat, t)
beta_t = extract(beta, t)
alpha_hat_prev_t = extract(alpha_hat_prev, t)
beta_hat_t = beta_t * (1 - alpha_hat_prev_t) / (1 - alpha_hat_t) # similar to beta
noise = tf.random.normal(shape=x.shape)
""" DDPM """
direction_point = 1 / tf.sqrt(alpha_t) * (x - (beta_t / (tf.sqrt(1 - alpha_hat_t))) * predicted_noise) # mu
random_noise = beta_t * noise # stddev
denoised_x = direction_point + random_noiseImprovement
Improved DDPM에서는 DDPM에서 분산에 상수를 사용한 것을 지적하며 분산을 매개변수화 하여 VLB loss를 추가하고 몇 가지 추가적인 향상 방법도 제안했습니다.
DDIM 에서는 순방향 프로세스가 더 이상 diffusion이 아니더라도 랜덤 가우스 노이즈의 표준 편차를 0으로 지정하여 모델을 결정론적으로 바꾸었습니다. 장점으로는 빠르고 고품질의 추론, 생성 결과가 일관되고, 보간이 가능합니다.

Architecture Improvements
아키텍처 변경사항
- model의 크기를 일정하게 유지하며 너비에 대한 시간이 증가
- attention head 수를 늘림
- 32x32, 16x16, 8x8 해상도에서 attention 사용 (원래는 16x16에서만 사용함)
- NVAE 논문에 의하여 업샘플링 및 다운샘플링하기 위해 BigGAN의 잔차 블록 사용
- 1 /√2 로 잔차 연결 재조정
Adaptive Group Normalization
그룹 정규화 이후 각 잔차 블록에 시간 단계와 클래스 임베딩을 통합하는 적응형 그룹 정규화(AdaGN) 사용합니다.

Classifier Guidance
잡음이 있는 이미지 xt에 대해 분류기 pφ(y|xt, t)를 훈련한 다음 gradient ∇xtlog pφ(y|xt, t)를 사용하여 임의의 class label y로 확산 샘플링 프로세스를 안내할 수 있다. 간결화된 수식은 pφ(y|xt, t) = pφ(y|xt), εθ(xt, t) = εθ(xt)와 같습니다.
Conditional Reverse Noising Process
Sampling (원래는 y를 조건으로 하는 xT를 샘플링해야 하지만 노이즈가 충분히 많으면 어차피 정규분포라 상관없다고 합니다.)

Diffusion models의 목적은 시간 단계 t+1에서 xt를 예측하는 것입니다.
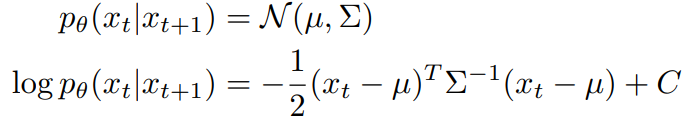
따라서 ||Σ|| → 0인 무한 확산 단계에서, xt = µ 부근의 테일러 확장을 이용하여 다음과 같이 근사할 수 있다.
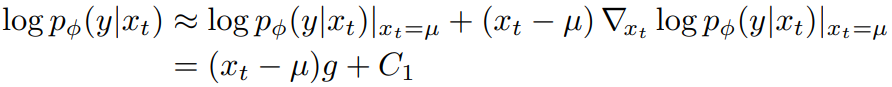
아래식으로 조건부 변환 연산은 무조건 변환 연산과 유사하지만 평균이 Σg 만큼 이동한 정규 분포로 근사될 수 있음을 발견했습니다.
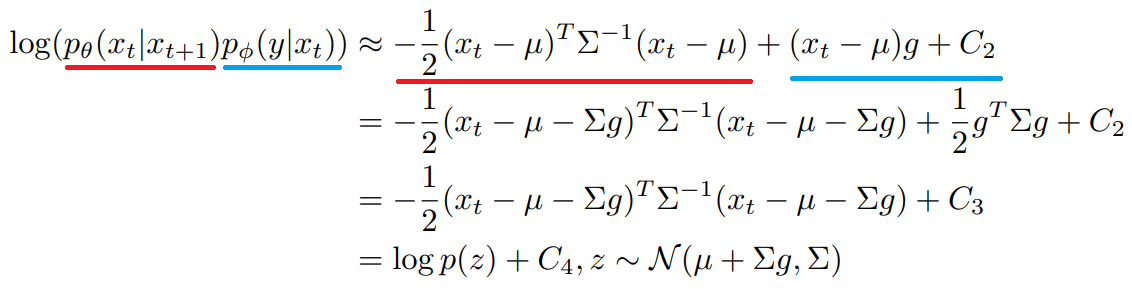
Conditional Sampling for DDIM
이전 Session의 유도는 확률적 Diffusion sampling process에만 유효하며 DDIM 같은 결정론적 방법에는 적용할 수 없다.
이를 위해 score-based conditioning trick을 사용한다.
추가된 노이즈를 예측하는 모델 εθ(xt)가 있는 경우 score 함수를 유도하는 데 사용할 수 있다.
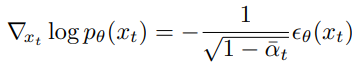
이때 조건부 공식을 score function으로 대체합니다.
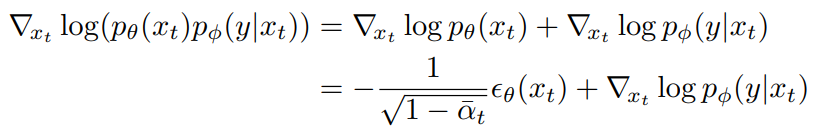
마지막으로 공동 분포의 점수에 해당하는 새로운 예측을 정의합니다.
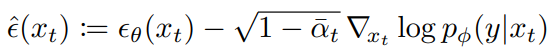
Scaling Classifier Gradients
분류기는 ImageNet에서 훈련을 진행하였습니다.
최종 출력에서 클래스 불일치가 발견돼 gradient 계수를 추가하고 늘렸더니 불일치 없어졌습니다.
(웰시코기 클래스. 왼쪽 - 1, 오른쪽 - 10)

Gradient 계수를 높이면 다양성을 희생하고 품질이 좋아집니다.