소프트맥스 회귀(Softmax Regression)
이번에는 3개 이상의 선택지 중에서 1개를 고르는 다중 클래스 분류 문제를 위한 소프트맥스 회귀(Softmax Regression)에 대해서 포스팅해보겠습니다.
다중 클래스 분류(Multi-class Classification)
이진 분류가 두 개의 선택지 중 하나를 고르는 문제였다면, 세 개 이상의 선택지 중 하나를 고르는 문제를 다중 클래스 분류라고 합니다. 아래의 붓꽃 품종 예측 데이터는 꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이로부터 setosa, versicolor, virginica라는 3개의 품종 중 어떤 품종인지를 예측하는 문제를 위한 데이터로 전형적인 다중 클래스 분류 문제를 위한 데이터입니다.
| SepalLengthCm(x1) | SepalWidthCm(x2) | PetalLengthCm(x3) | PetalWidthCm(x4) | Species(y) |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 5.8 | 2.6 | 4.0 | 1.2 | versicolor |
| 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 5.6 | 2.8 | 4.9 | 2.0 | virginica |
이 전체 확률의 합계가 1이 되도록 하여 전체 선택지에 걸친 확률로 바꾸면 예를 들어 샘플 데이터가 입력으로 들어오면 모델이 setosa일 확률이 0.7, versicolor일 확률 0.05, virginica일 확률이 0.25과 같이 세 개의 확률의 총 합이 1인 예측값을 얻을 수 있습니다. 그리고 이 경우 확률값이 가장 높은 setosa로 예측한 것으로 간주하고자 합니다. 이럴 때 사용할 수 있는 것이 소프트맥스 함수입니다.
소프트맥스 함수(Softmax function)
소프트맥스 함수는 선택해야 하는 선택지의 총 개수를 k라고 할 때, k차원의 벡터를 입력받아 각 클래스에 대한 확률을 추정합니다. 우선 수식에 대해 설명하고, 그 후에는 그림으로 이해해보겠습니다.
1) 소프트맥스 함수의 이해
k차원의 벡터에서 i번째 원소zi를 , i번째 클래스가 정답일 확률을 pi로 나타낸다고 하였을 때 소프트맥스 함수는 pi를 다음과 같이 정의합니다.

위에서 풀어야하는 문제의 경우 k=3이므로 3차원 벡터 의 입력을 받으면 소프트맥스 함수는 아래와 같은 출력을 리턴합니다.
여기서 분류하고자하는 3개의 클래스는 virginica, setosa, versicolor이므로 이는 결국 주어진 입력이 virginica일 확률, setosa일 확률, versicolor일 확률을 나타내는 값을 의미합니다. 여기서는 i가 1일 때는 virginica일 확률을 나타내고, 2일 때는 setosa일 확률, 3일때는 versicolor일 확률이라고 지정하였다고 합시다. 이 지정 순서는 문제를 풀고자 하는 사람의 무작위 선택입니다. 이에따라 식을 문제에 맞게 다시 쓰면 아래와 같습니다.
분류하고자 하는 클래스가 k개일 때, k차원의 벡터를 입력받아서 모든 벡터 원소의 값을 0과 1사이의 값으로 값을 변경하여 다시 k차원의 벡터를 반환한다는 내용을 식으로 기재했습니다. 방금 배운 개념을 그림을 통해 다시 설명해보겠습니다.
여기서는 샘플 데이터를 1개씩 입력으로 받아 처리한다고 가정해봅시다. 즉, 배치 크기가 1입니다.
위의 그림에는 두 가지 의문이 있습니다. 첫번째 질문은 소프트맥스 함수의 입력에 대한 의문입니다. 하나의 샘플 데이터는 4개의 독립 변수 x를 가지는데 이는 모델이 4차원 벡터를 입력으로 받음을 의미합니다. 그런데 소프트맥스의 함수의 입력으로 사용되는 벡터는 벡터의 차원이 분류하고자 하는 클래스의 개수가 되어야 하므로 어떤 가중치 연산을 통해 3차원 벡터로 변환되어야 합니다. 위의 그림에서는 소프트맥스 함수의 입력으로 사용되는 3차원 벡터를 z로 표현하였습니다.
샘플 데이터 벡터를 소프트맥스 함수의 입력 벡터로 차원을 축소하는 방법으로 소프트맥스 함수의 입력 벡터 z의 차원수만큼 결과값이 나오도록 가중치 곱을 진행합니다. 위의 그림에서 화살표는 총 (4 × 3 = 12) 12개이며 전부 다른 가중치를 가지고, 학습 과정에서 점차적으로 오차를 최소화하는 가중치로 값이 변경됩니다.
두번째 질문은 오차 계산 방법에 대한 의문입니다. 소프트맥스 함수의 출력은 분류하고자하는 클래스의 개수만큼 차원을 가지는 벡터로 각 원소는 0과 1사이의 값을 가집니다. 이 각각은 특정 클래스가 정답일 확률을 나타냅니다. 여기서는 첫번째 원소인 p1은 virginica가 정답일 확률, 두번째 원소인 p2는 setosa가 정답일 확률, 세번째 원소인 p3은 versicolor가 정답일 확률로 고려하고자 합니다. 그렇다면 이 예측값과 비교를 할 수 있는 실제값의 표현 방법이 있어야 합니다. 소프트맥스 회귀에서는 실제값을 원-핫 벡터로 표현합니다.
각 실제값의 정수 인코딩은 1, 2, 3이 되고 이에 원-핫 인코딩을 수행하여 실제값을 원-핫 벡터로 수치화한 것을 보여줍니다.
예를 들어 현재 풀고 있는 샘플 데이터의 실제값이 setosa라면 setosa의 원-핫 벡터는 [0 1 0]입니다. 이 경우, 예측값과 실제값의 오차가 0이 되는 경우는 소프트맥스 함수의 결과가 [0 1 0]이 되는 경우입니다. 이 두 벡터의 오차를 계산하기 위해서 소프트맥스 회귀는 비용 함수로 크로스 엔트로피 함수를 사용합니다.
앞서 배운 선형 회귀나 로지스틱 회귀와 마찬가지로 오차로부터 가중치를 업데이트 합니다.
소프트맥스 회귀를 벡터와 행렬 연산으로 이해해봅시다. 입력을 특성(feature)의 수만큼의 차원을 가진 입력 벡터 x라고 하고, 가중치 행렬W을 , 편향 b을 라고 하였을 때, 소프트맥스 회귀에서 예측값을 구하는 과정을 벡터와 행렬 연산으로 표현하면 아래와 같습니다.
여기서 4는 특성의 수이며 3은 클래스의 개수에 해당됩니다.
원-핫 벡터의 무작위성
꼭 실제값을 원-핫 벡터로 표현해야만 다중 클래스 분류 문제를 풀 수 있는 것은 아니지만, 대부분의 다중 클래스 분류 문제가 각 클래스 간의 관계가 균등하다는 점에서 원-핫 벡터는 이러한 점을 표현할 수 있는 적절한 표현 방법입니다.
다수의 클래스를 분류하는 문제에서는 이진 분류처럼 2개의 숫자 레이블이 아니라 클래스의 개수만큼 숫자 레이블이 필요합니다. 그런데 일반적인 다중 클래스 분류 문제에서 레이블링 방법으로는 위와 같은 정수 인코딩이 아니라 원-핫 인코딩을 사용하는 것이 보다 클래스의 성질을 잘 표현하였다고 할 수 있습니다.
Banana, Tomato, Apple라는 3개의 클래스가 존재하는 문제가 있다고 해봅시다. 레이블은 정수 인코딩을 사용하여 각각 1, 2, 3을 부여하였습니다. 손실 함수로 선형 회귀 실습에서 배운 평균 제곱 오차 MSE를 사용하면 정수 인코딩이 어떤 오해를 불러일으킬 수 있는지 확인할 수 있습니다. 아래의 식은 앞서 선형 회귀에서 배웠던 MSE를 다시 그대로 가져온 것입니다.
직관적인 오차 크기 비교를 위해 평균을 구하는 수식은 제외하고 제곱 오차로만 판단해봅시다.
실제값이 Tomato일때 예측값이 Banana이었다면 제곱 오차는 다음과 같습니다. -> 1
실제값이 Apple일때 예측값이 Banana이었다면 제곱 오차는 다음과 같습니다. -> 4
즉, Banana과 Tomato 사이의 오차보다 Banana과 Apple의 오차가 더 큽니다. 이는 기계에게 Banana가 Apple보다는 Tomato에 더 가깝다는 정보를 주는 것과 다름없습니다. 더 많은 클래스에 대해서 정수 인코딩을 수행했다고 해봅시다.
{Banana :1, Tomato :2, Apple :3, Strawberry :4, ... Watermelon :10}
이 정수 인코딩은 Banana가 Watermelon보다는 Tomato에 더 가깝다는 의미를 담고 있습니다. 이는 사용자가 부여하고자 했던 정보가 아닙니다. 이러한 정수 인코딩의 순서 정보가 도움이 되는 분류 문제도 물론 있습니다. 바로 각 클래스가 순서의 의미를 갖고 있어서 회귀를 통해서 분류 문제를 풀 수 있는 경우입니다. 예를 들어 {baby, child, adolescent, adult}나 {1층, 2층, 3층, 4층}이나 {10대, 20대, 30대, 40대}와 같은 경우가 이에 해당됩니다. 하지만 일반적인 분류 문제에서는 각 클래스는 순서의 의미를 갖고 있지 않으므로 각 클래스 간의 오차는 균등한 것이 옳습니다. 정수 인코딩과 달리 원-핫 인코딩은 분류 문제 모든 클래스 간의 관계를 균등하게 분배합니다.
아래는 세 개의 카테고리에 대해서 원-핫 인코딩을 통해서 레이블을 인코딩했을 때 각 클래스 간의 제곱 오차가 균등함을 보여줍니다.
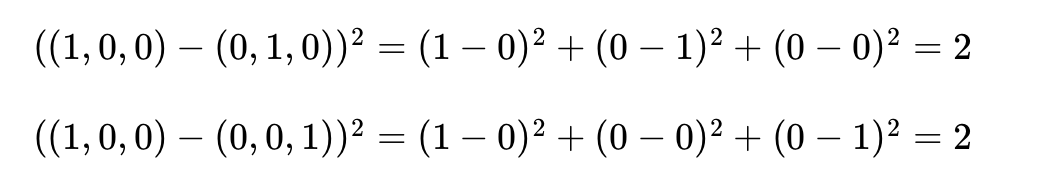
다르게 표현하면 모든 클래스에 대해서 원-핫 인코딩을 통해 얻은 원-핫 벡터들은 모든 쌍에 대해서 유클리드 거리를 구해도 전부 유클리드 거리가 동일합니다. 원-핫 벡터는 이처럼 각 클래스의 표현 방법이 무작위성을 가진다는 점을 표현할 수 있습니다. 다만, 원-핫 벡터의 관계의 무작위성은 때로는 단어의 유사성을 구할 수 없다는 단점으로 언급되기도 합니다.
비용함수(Cost function)
소프트맥스 회귀에서는 비용 함수로 크로스 엔트로피 함수를 사용합니다. 여기서는 소프트맥스 회귀에서의 크로스 엔트로피 함수뿐만 아니라, 다양한 표기 방법에 대해서 이해해보겠습니다.
1) 크로스 엔트로피 함수
아래에서 y는 실제값을 나타내며, k는 클래스의 개수로 정의합니다. yj는 실제값 원-핫 벡터의 j번째 인덱스를 의미하며, pj는 샘플 데이터가j번째 클래스일 확률을 나타냅니다.
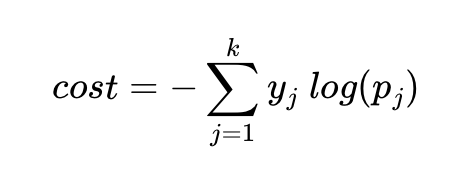
이를 n개의 전체 데이터에 대한 평균을 구한다고 하면 최종 비용 함수는 다음과 같습니다.
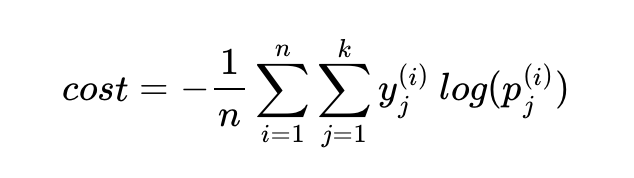
2) 이진 분류에서의 크로스 엔트로피 함수
로지스틱 회귀에서 배운 크로스 엔트로피 함수식과 달라보이지만, 본질적으로는 동일한 함수식입니다. 로지스틱 회귀의 크로스 엔트로피 함수식으로부터 소프트맥스 회귀의 크로스 엔트로피 함수식을 도출해봅시다.
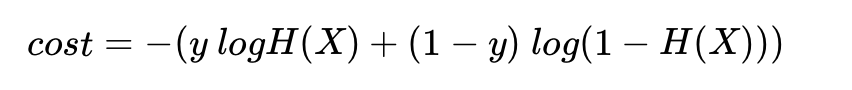
로지스틱 회귀에서 배웠던 크로스 엔트로피의 함수식을 보여줍니다. 이를 식으로 표현하면 아래와 같습니다.
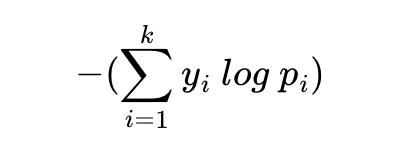
위의 식은 결과적으로 소프트맥스 회귀의 식과 동일합니다. 역으로 소프트맥스 회귀에서 로지스틱 회귀의 크로스 엔트로피 함수식을 얻는 것은 k를 2로 하고, y1과 y2를 각각 y와 1-y로 치환하고, p1와 p2를 각각 H(X)와 1-H(X)로 치환하면 됩니다.정리하면 소프트맥스 함수의 최종 비용 함수에서 k가 2라고 가정하면 결국 로지스틱 회귀의 비용 함수와 같습니다.
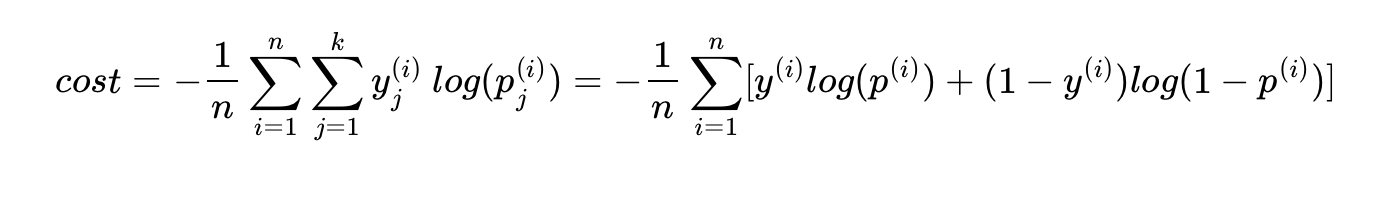
출처 : https://wikidocs.net/35476
'머신러닝 & 딥러닝 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 로지스틱 회귀(Logistic Regression) (0) | 2023.05.31 |
|---|---|
| [머신러닝] 선형 회귀(Linear Regression) (0) | 2023.05.31 |
| [머신러닝] 머신러닝 개념 훓어보기 (0) | 2023.05.23 |