학교에서 인공지능 수업과 '딥러닝을 통한 자연어 입문'에 나온 머신러닝 및 딥 러닝의 기초적인 내용을 정리한 포스팅입니다.
머신러닝이란?
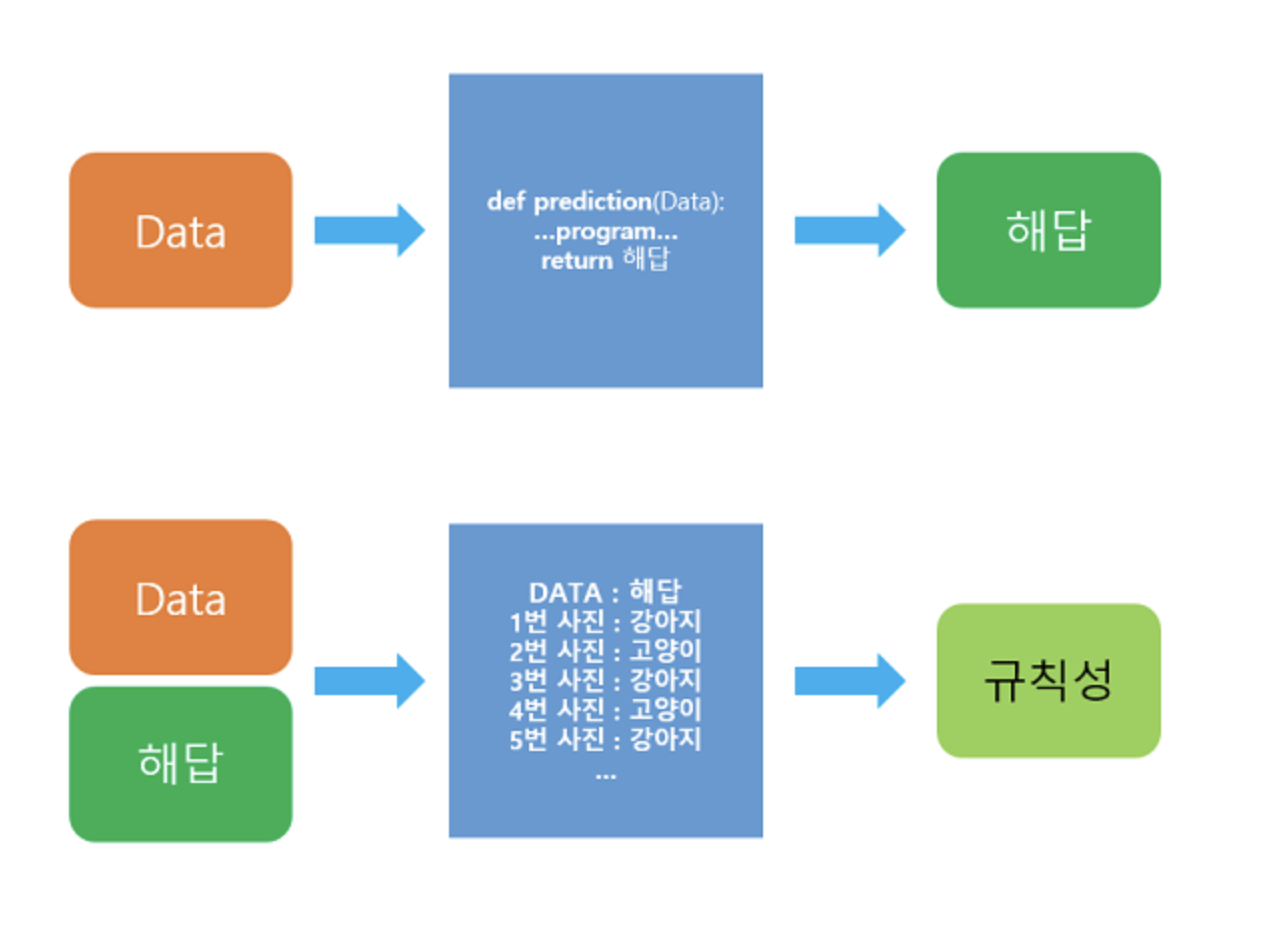
위에는 일반적인 프로그래밍 방법이고 아래는 머신러닝의 방법입니다.
머신 러닝은 데이터가 주어지면, 기계가 스스로 데이터로부터 규칙성을 찾는 것에 집중합니다. 주어진 데이터로부터 규칙성을 찾는 과정을 우리는 훈련(training) 또는 학습(learning)이라고 합니다.
일단 규칙성을 발견하고나면, 그 후에 들어오는 새로운 데이터에 대해서 발견한 규칙성을 기준으로 정답을 찾아내는데 이는 기존의 프로그래밍 방식으로 접근하기 어려웠던 문제의 해결책이 되기도 합니다.
여기서 머신러닝과 딥러닝의 차이점으로는 딥러닝은 머신 러닝의 한 갈래이고 “인공 신경망”이라는 알고리즘을 계층으로 구성하여 자체적으로 배우고 지능적인 결정을 내릴 수 있게 만들고 이는 자연어 처리에 효과적입니다.
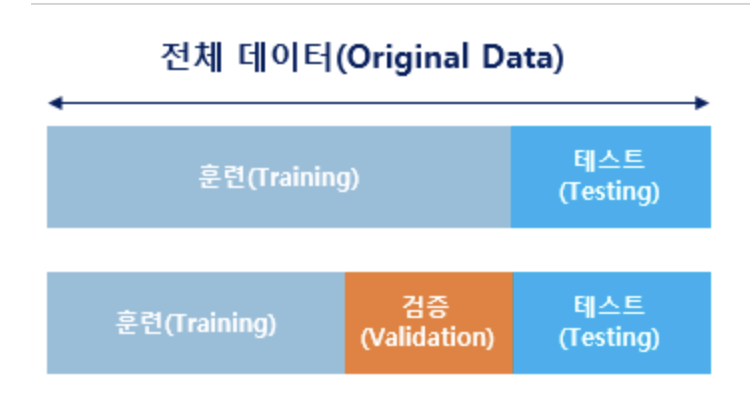
머신러닝에는 일반적으로 훈련, 검증, 테스트 3단계로 데이터를 나누며 학습하기 전에 셋팅을 진행합니다.
여기서 검증용 데이터는 모델의 성능을 평가하는 것이 아니라 모델의 성능을 조절하여 과적합(overfitting)이 되는지 체크하고 하이퍼파라미터를 조정을 위한 용도입니다.
- 하이퍼파라미터(초매개변수) : 모델의 성능에 영향을 주는 사람이 값을 지정하는 변수.
- 매개변수 : 가중치와 편향. 학습을 하는 동안 값이 계속해서 변하는 수.
가중치와 편향과 같은 매개변수는 사용자가 결정해주는 값이 아니라 모델이 학습하는 과정에서 얻어지는 값입니다. 훈련용 데이터로 훈련을 모두 시킨 모델은 검증용 데이터를 사용하여 정확도를 검증하며 하이퍼파라미터를 튜닝(tuning) 합니다. 검증용 데이터에 대해서 높은 정확도를 얻도록 하이퍼파라미터의 값을 바꿔보는 것입니다. 이렇게 튜닝하는 과정에서 모델은 검증용 데이터의 정확도를 높이는 방향으로 점차적으로 수정됩니다.
마무리로 튜닝 과정을 모두 끝내고 모델의 최종 평가를 하고자 한다면, 이제 검증용 데이터로 모델을 평가하는 것은 적합하지 않습니다.
이유는 모델은 검증용 데이터의 정확도를 높이기 위해서 수정되어져 온 모델이기 때문입니다.
분류(Classification)와 회귀(Regression)
머신러닝에는 다양한 분류와 회귀 방법이 존재하는데 다음 포스팅에 대표적인 선형 회귀와 로지스틱 회귀를 알아보도록 해보겠습니다.
1) 이진 분류 문제(Binary Classificaion)
이진 분류는 주어진 입력에 대해서 두 개의 선택지 중 하나의 답을 선택해야 하는 경우를 말합니다. 종합 시험 성적표를 보고 최종적으로 합격, 불합격인지 판단하는 문제, 메일을 보고나서 정상 메일, 스팸 메일인지를 판단하는 문제 등이 이에 속합니다.
2) 다중 클래스 분류(Multi-class Classification)
다중 클래스 분류는 주어진 입력에 대해서 세 개 이상의 선택지 중에서 답을 선택해야 하는 경우를 말합니다. 예를 들어 서점 직원이 일을 하는데 과학, 영어, IT, 학습지, 만화라는 레이블이 붙어있는 5개의 책장이 있다고 합시다. 새 책이 입고되면, 이 책은 다섯 개의 책장 중에서 분야에 맞는 적절한 책장에 책을 넣어야 합니다. 이 경우는 현실에서의 다중 클래스 분류 문제라고 할 수 있겠습니다.
3) 회귀 문제(Regression)
회귀 문제는 분류 문제처럼 둘 중 하나를 선택해야 한다거나, 책이 입고되었을 때 5개의 책장 중 하나의 책장을 골라야하는 경우처럼 정답이 몇 개의 정해진 선택지 중에서 정해져 있는 경우가 아니라 어떠한 연속적인 값의 범위 내에서 예측값이 나오는 경우를 말합니다.
지도 학습과 비지도 학습
머신 러닝은 크게 지도 학습, 비지도 학습, 강화 학습으로 나눕니다. 여기서 강화 학습은 시행착오(Trial and Error)를 통해 실수와 보상을 통하여 학습을 하는 방법인데 이 포스팅에서는 강화 학습 대신에 자기지도 학습(Self-Supervised Learning, SSL)을 이야기하겠습니다.
1) 지도 학습(Supervised Learning)
지도 학습이란 레이블(Label)이라는 정답과 함께 학습하는 것을 말합니다. 자연어 처리는 대부분 지도 학습에 속합니다. 이유로는 앞으로 우리가 풀게 될 자연어 처리의 많은 문제들은 레이블이 존재하는 경우가 많기 때문입니다. 그리고 여기서 레이블은 y 혹은 실제값이라고도 불립니다.
2) 비지도 학습(Unsupervised Learning)
비지도 학습은 데이터에 별도의 레이블이 없이 학습하는 것을 말합니다. 예를 들어 텍스트 처리 분야의 토픽 모델링 알고리즘인 LSA나 LDA는 비지도 학습에 속합니다
3) 자기지도 학습(Self-Supervised Learning, SSL)
레이블이 없는 데이터가 주어지면, 모델이 학습을 위해서 스스로 데이터로부터 레이블을 만들어서 학습하는 경우를 자기지도 학습이라고 합니다. 대표적인 예시로는 Word2Vec과 같은 워드 임베딩 알고리즘이나, BERT와 같은 언어 모델의 학습 방법을 들 수 있습니다.
샘플(Sample)과 특성(Feature)
많은 머신 러닝 문제가 1개 이상의 독립 변수 x를 가지고 종속 변수 y를 예측하는 문제입니다. 머신 러닝 모델 중 특히 인공 신경망은 독립 변수, 종속 변수, 가중치, 편향 등을 행렬 연산을 통해 연산하는 경우가 많습니다. 앞으로 인공 신경망을 배우게되면 훈련 데이터를 행렬로 표현하는 경우를 많이 보게 됩니다. 독립 변수 x의 행렬을 X라고 하였을 때, 독립 변수의 개수가 n개이고 데이터의 개수가 m인 행렬 X는 다음과 같습니다.
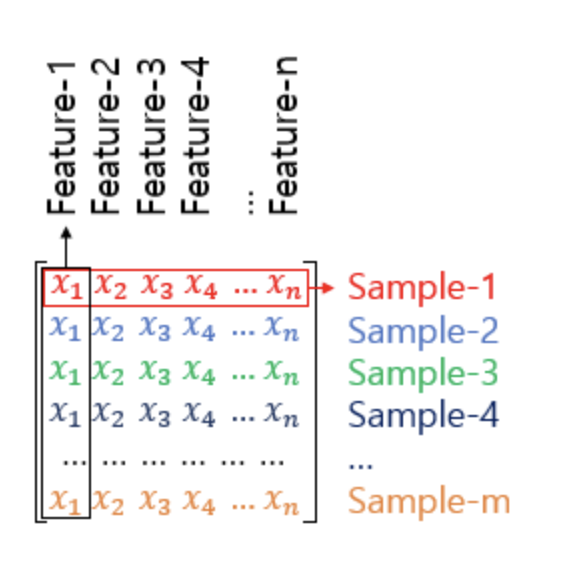
샘플(Sample) : 하나의 데이터. 행렬 관점에서는 하나의 행
특성(Feature) : 종속 변수 y를 예측하기 위한 각각의 독립 변수 x
혼동 행렬(Confusion Matrix)
머신 러닝에서는 맞춘 문제수를 전체 문제수로 나눈 값을 정확도(Accuracy)라고 합니다. 하지만 정확도는 맞춘 결과와 틀린 결과에 대한 세부적인 내용을 알려주지는 않습니다. 이를 위해서 사용하는 것이 혼동 행렬(Confusion Matrix)입니다. 예를 들어 참(True)와 거짓(False) 둘 중 하나를 예측하는 문제였다고 가정해봅시다. 아래의 혼동 행렬에서 각 열은 예측값을 나타내며, 각 행은 실제값을 나타냅니다.
| 예측 | 참예측 | 거짓 |
| 실제 참 | TP | FN |
| 실제 거짓 | FP | TN |
머신 러닝에서는 다음과 같은 네 가지 케이스에 대해서 각각 TP, FP, FN, TN을 정의합니다.
- True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
- False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
- True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
이 개념을 사용하면 정밀도(Precision)과 재현율(Recall)이 됩니다.
1) 정밀도(Precision)
정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율입니다.
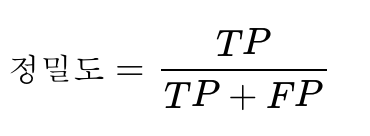
2) 재현율(Recall)
재현율이란 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율입니다.

3) 정확도(Accuracy)
정확도(Accuracy)는 우리가 일반적으로 실생활에서도 가장 많이 사용하는 지표입니다. 전체 예측한 데이터 중에서 정답을 맞춘 것에 대한 비율입니다. TP, FP, FN, TN을 가지고 수식을 설명하면 다음과 같습니다.
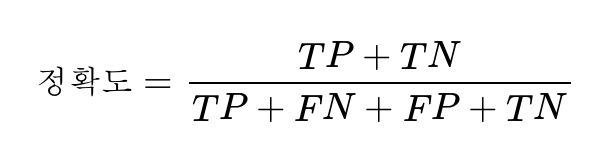
그런데 Accuracy로 성능을 예측하는 것이 적절하지 않은 때가 있습니다. 비가 오는 날을 예측하는 모델을 만들었다고 했을 때, 200일 동안 총 6일만 비가 왔다고 해봅시다. 그런데 이 모델은 200일 내내 날씨가 맑았다고 예측했습니다. 이 모델은 200번 중 총 6회 틀렸습니다. 194/200=0.97이므로 정확도는 97%입니다. 하지만 정작 비가 온 날은 하나도 못 맞춘 셈입니다.
이렇게 실질적으로 더 중요한 경우에 대한 데이터가 전체 데이터에서 너무 적은 비율을 차지한다면 정확도는 좋은 측정 지표가 될 수 없습니다. 이런 경우에는 F1-Score를 사용하며, 이에 대해서는 태깅 작업에서 개체명 인식 챕터(named entity)에서 용어가 나옵니다.
과적합(Overfitting)과 과소 적합(Underfitting)
과적합(Overfitting) : 과적합이란 훈련 데이터를 과하게 학습한 경우를 말합니다. 머신 러닝 모델이 학습에 사용하는 훈련 데이터는 실제로 앞으로 기계가 풀어야 할 현실의 수많은 문제에 비하면 극히 일부에 불과한 데이터입니다. 기계가 훈련 데이터에 대해서만 과하게 학습하면 성능 측정을 위한 데이터인 테스트 데이터나 실제 서비스에서는 정확도가 좋지 않은 현상이 발생합니다.
그리고 과적합 상황에서는 훈련 데이터에 대해서는 오차가 낮지만, 테스트 데이터에 대해서는 오차가 커집니다. 아래의 그래프는 과적합 상황에서 발생할 수 있는 훈련 데이터에 대한 훈련 횟수에 따른 훈련 데이터의 오차와 테스트 데이터의 오차(또는 손실, loss라고도 부릅니다.)의 변화를 보여줍니다.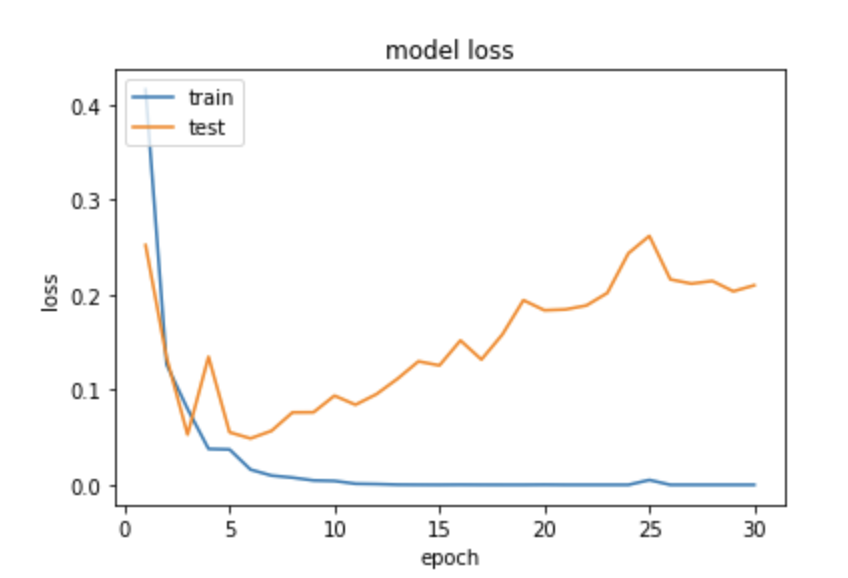
과소적합(Underfitting) : 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태입니다. 과소 적합은 훈련 자체가 부족한 상태이므로 훈련 횟수인 epoch가 지나치게 적으면 발생할 수 있습니다. 과대 적합과는 달리 과소 적합은 훈련 자체를 너무 적게한 상태이므로 훈련 데이터에 대해서도 정확도가 낮다는 특징이 있습니다.
마지막으로 일반적으로 과적합이 발생하였을 때 실행하는 순서가 있습니다.
- Step 1. 주어진 데이터를 훈련 데이터, 검증 데이터, 테스트 데이터로 나눈다. 가령, 6:2:2 비율로 나눌 수 있다.
- Step 2. 훈련 데이터로 모델을 학습한다. (에포크 +1)
- Step 3. 검증 데이터로 모델을 평가하여 검증 데이터에 대한 정확도와 오차(loss)를 계산한다.
- Step 4. 검증 데이터의 오차가 증가하였다면 과적합 징후이므로 학습 종료 후 Step 5로 이동, 아니라면 Step 2.로 재이동한다.
- Step 5. 모델의 학습이 종료되었으니 테스트 데이터로 모델을 평가한다.
출처 : https://wikidocs.net/32012
06-02 머신 러닝 훑어보기
머신 러닝의 특징을 이해하고, 주요 용어에 미리 친숙해져봅시다. ## 1. 머신 러닝 모델의 평가  (0) | 2023.05.31 |
|---|---|
| [머신러닝] 로지스틱 회귀(Logistic Regression) (0) | 2023.05.31 |
| [머신러닝] 선형 회귀(Linear Regression) (0) | 2023.05.31 |