이번 포스팅에서는 워드 임베딩에 대하여 알아보도록 하겠습니다.
워드 임베딩(Word Embedding)
워드 임베딩(Word Embedding)은 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환합니다.
희소 표현(Sparse Representation)
앞서 원-핫 인코딩을 통해서 나온 원-핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현되는 벡터 표현 방법이었습니다. 이렇게 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 희소 표현(sparse representation)이라고 합니다. 원-핫 벡터는 희소 벡터(sparse vector)입니다.
이러한 희소 벡터의 문제점은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다는 점입니다. 원-핫 벡터로 표현할 때는 갖고 있는 코퍼스에 단어가 10,000개였다면 벡터의 차원은 10,000이어야만 했습니다. 심지어 그 중에서 단어의 인덱스에 해당되는 부분만 1이고 나머지는 0의 값을 가져야만 했습니다. 단어 집합이 클수록 고차원의 벡터가 됩니다. 예를 들어 단어가 10,000개 있고 인덱스가 0부터 시작하면서 강아지란 단어의 인덱스는 4였다면 원 핫 벡터는 이렇게 표현되어야 했습니다.
Ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이때 1 뒤의 0의 수는 9995개.
이러한 벡터 표현은 공간적 낭비를 불러일으킵니다. 희소 표현의 일종인 DTM도 다른 많은 문서에서는 해당 특정 문서에 등장했던 단어들이 전부 등장하지 않는다면 역시나 행렬의 많은 값이 0이 되면서 공간적 낭비를 일으킵니다. 원-핫 벡터와 같은 희소 벡터의 문제점은 단어의 의미를 표현하지 못한다는 점입니다.
밀집 표현(Dense Representation)
희소 표현과 반대되는 표현으로 밀집 표현(dense representation)이 있습니다. 밀집 표현은 벡터의 차원을 단어 집합의 크기로 상정하지 않습니다. 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춥니다. 또한, 이 과정에서 더 이상 0과 1만 가진 값이 아니라 실수값을 가지게 됩니다. 아래의 희소 표현의 예를 다시한번 보면,
Ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이때 1 뒤의 0의 수는 9995개. 차원은 10,000
예를 들어 10,000개의 단어가 있을 때 강아지란 단어를 표현하기 위해서는 위와 같은 표현을 사용했습니다. 하지만 밀집 표현을 사용하고, 사용자가 밀집 표현의 차원을 128로 설정한다면, 모든 단어의 벡터 표현의 차원은 128로 바뀌면서 모든 값이 실수가 됩니다.
Ex) 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
이 경우 벡터의 차원이 조밀해졌다고 하여 밀집 벡터(dense vector)라고 합니다.
워드 임베딩(Word Embedding)
단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 합니다. 그리고 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 합니다.
워드 임베딩 방법론으로는 LSA, Word2Vec, FastText, Glove 등이 있습니다. 케라스에서 제공하는 도구인 Embedding()는 앞서 언급한 방법들을 사용하지는 않지만, 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법을 사용합니다. 아래의 표는 앞서 배운 원-핫 벡터와 지금 배우고 있는 임베딩 벡터의 차이를 보여줍니다.
| 원-핫 벡터임 | 임베딩 벡터 | |
| 차원 | 고차원(단어 집합의 크기) | 저차원 |
| 다른 표현 | 희소 벡터의 일종 | 밀집 벡터의 일종 |
| 표현 방법 | 수동 | 훈련 데이터로부터 학습함 |
| 값의 타입 | 1과 0 | 실수 |
1. 워드투벡터(Word2Vec)
워드투벡터란 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화 할 수 있는 방법입니다.
앞에서 희소 표현에 대하여 알아보았는데 이러한 표현 방식으로는 단어 벡터간 유의미한 유사성을 찾아보기가 힘들고, 대안으로 단어의 의미를 다차원 공간에 벡터화하는 방법을 사용하는데 이를 분산 표현(distributed representaion)이라고 합니다. 그리고 분산 표현을 이용하여 단어간 의미적 유사성을 벡터화하는 작업을 워드 임베딩(embedding)이라고 부르며, 이렇게 표현한 벡터를 임베딩 벡터라고 합니다.
또한 분산 표현에 대하여도 알아보았는데 앞에서 희소 표현은 고차원에 각 차원이 분리된 표현 방법이라면, 분산 표현은 저차원에서 단어의 의미를 여러 차원에다가 분산시키는 것으로 단어 벡터 간 유의미한 유사도를 계산할 수 있습니다.
이를 대표하는 방식이 Word2Vec입니다.
Word2Vec의 학습 방식의 종류
1) CBOW(Continuous Bag of Words) : 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측 하는 방법입니다.
2) Skip-Gram : 중간에 있는 단어들로 주변 단어들을 예측합니다.
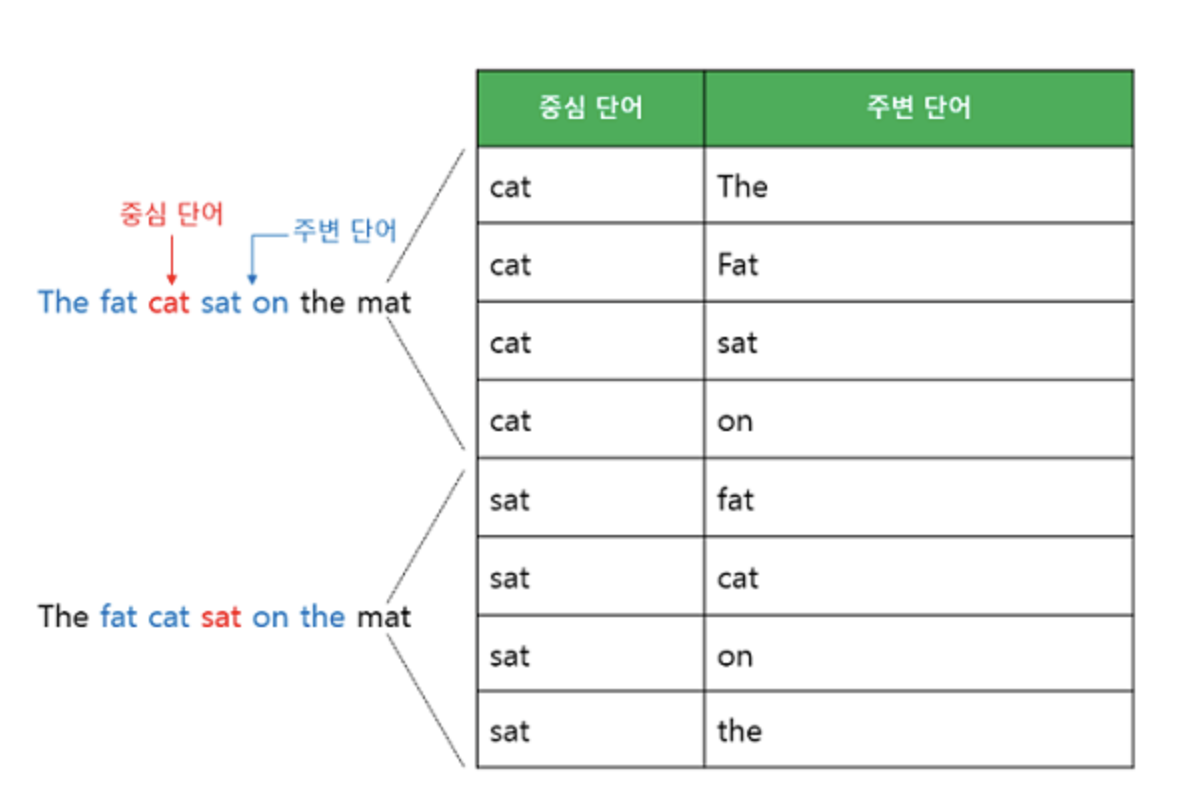
예문 : "The fat cat sat on the mat"
1) CBOW : ['The', 'fat', 'cat', 'on', 'the', 'mat']으로부터 sat을 예측, 이때 sat은 중심 단어(center word)이고, 예측에 사용되는 단어들을 주변 단어(context word)라고 합니다.
중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정해야 하는데 이 범위를 윈도우(window)라고 합니다. 예를 들어 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 입력으로 사용합니다. 윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n입니다.
윈도우 크기가 정해지면 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는데 이 방법을 슬라이딩 윈도우(sliding window)라고 합니다.

위 그림에서 좌측의 중심 단어와 주변 단어의 변화는 윈도우 크기가 2일때, 슬라이딩 윈도우가 어떤 식으로 이루어지면서 데이터 셋을 만드는지 보여줍니다. Word2Vec에서 입력은 모두 원-핫 벡터가 되어야 하는데, 우측 그림은 중심 단어와 주변 단어를 어떻게 선택했을 때에 따라서 각각 어떤 원-핫 벡터가 되는지를 보여줍니다. 위 그림은 결국 CBOW를 위한 전체 데이터 셋을 보여주는 것입니다.
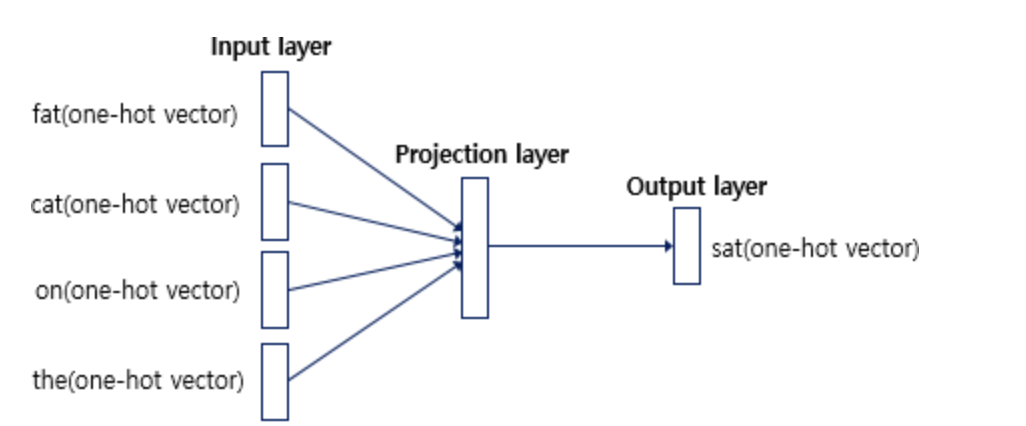
2) Skip-gram : CBOW에서는 주변 단어를 통해 중심 단어를 예측했다면, Skip-gram은 중심 단어에서 주변 단어를 예측합니다. 앞서 언급한 예문에 대해서 동일하게 윈도우 크기가 2일 때, 데이터셋은 다음과 같이 구성됩니다.
인공 신경망을 도식화해보면 아래와 같습니다.
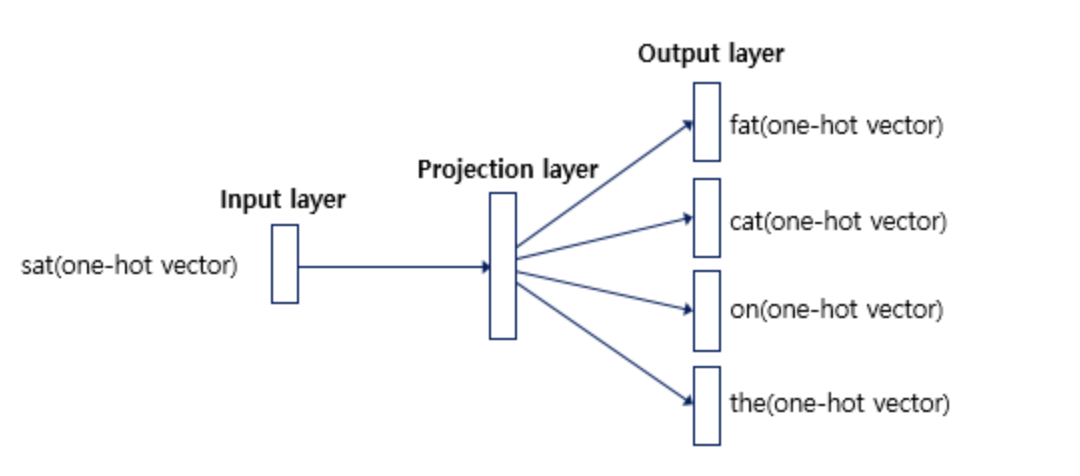
중심 단어에 대해서 주변 단어를 예측하므로 투사층에서 벡터들의 평균을 구하는 과정은 없습니다. 여러 논문에서 성능 비교를 진행했을 때 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있습니다.
아래는 gensim 패키지에서 제공하는 이미 구현된 Word2Vec을 사용하여 영어 데이터를 학습하는 코드입니다.
import nltk
nltk.download('punkt')import re
import urllib.request
import zipfile
from lxml import etree
from nltk.tokenize import word_tokenize, sent_tokenize# 데이터 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/ukairia777/tensorflow-nlp-tutorial/main/09.%20Word%20Embedding/dataset/ted_en-20160408.xml", filename="ted_en-20160408.xml")targetXML = open('/content/ted_en-20160408.xml', 'r', encoding='UTF8')
target_text = etree.parse(targetXML)
# xml 파일로부터 <content>와 </content> 사이의 내용만 가져온다.
parse_text = '\n'.join(target_text.xpath('//content/text()'))
# 정규 표현식의 sub 모듈을 통해 content 중간에 등장하는 (Audio), (Laughter) 등의 배경음 부분을 제거.
# 해당 코드는 괄호로 구성된 내용을 제거.
content_text = re.sub(r'\([^)]*\)', '', parse_text)
# 입력 코퍼스에 대해서 NLTK를 이용하여 문장 토큰화를 수행.
sent_text = sent_tokenize(content_text)
# 각 문장에 대해서 구두점을 제거하고, 대문자를 소문자로 변환.
normalized_text = []
for string in sent_text:
tokens = re.sub(r"[^a-z0-9]+", " ", string.lower())
normalized_text.append(tokens)
# 각 문장에 대해서 NLTK를 이용하여 단어 토큰화를 수행.
result = [word_tokenize(sentence) for sentence in normalized_text]print('총 샘플의 개수 : {}'.format(len(result)))총 샘플의 개수 : 273424# 샘플 3개만 출력
for line in result[:3]:
print(line)['here', 'are', 'two', 'reasons', 'companies', 'fail', 'they', 'only', 'do', 'more', 'of', 'the', 'same', 'or', 'they', 'only', 'do', 'what', 's', 'new']
['to', 'me', 'the', 'real', 'real', 'solution', 'to', 'quality', 'growth', 'is', 'figuring', 'out', 'the', 'balance', 'between', 'two', 'activities', 'exploration', 'and', 'exploitation']
['both', 'are', 'necessary', 'but', 'it', 'can', 'be', 'too', 'much', 'of', 'a', 'good', 'thing']from gensim.models import Word2Vec
from gensim.models import KeyedVectors
# size = 워드 벡터의 특징 값. 즉, 임베딩 된 벡터의 차원.
# window = 컨텍스트 윈도우 크기
# min_count = 단어 최소 빈도 수 제한 (빈도가 적은 단어들은 학습하지 않는다.)
# workers = 학습을 위한 프로세스 수
# sg = 0은 CBOW, 1은 Skip-gram.
model = Word2Vec(sentences=result, window=5, min_count=5, workers=4, sg=0)
model_result = model.wv.most_similar("man")
print(model_result)[('woman', 0.8420753479003906), ('guy', 0.8054128289222717), ('lady', 0.7491467595100403), ('soldier', 0.745265781879425), ('boy', 0.7427355647087097), ('gentleman', 0.7409957051277161), ('girl', 0.7261686325073242), ('friend', 0.669353723526001), ('kid', 0.6517231464385986), ('rabbi', 0.6509920954704285)]
2. 글로브(GloVe)
글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드대학에서 개발한 단어 임베딩 방법론입니다. 앞서 학습하였던 기존의 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 지적하며 이를 보완한다는 목적으로 나왔고, 실제로도 Word2Vec만큼 뛰어난 성능을 보여줍니다. 현재까지의 연구에 따르면 단정적으로 Word2Vec와 GloVe 중에서 어떤 것이 더 뛰어나다고 말할 수는 없고, 이 두 가지 전부를 사용해보고 성능이 더 좋은 것을 사용하는 것이 바람직합니다.
| LSA | Word2Vec | |
| 정의 | 문서에서의 각 단어의 빈도수를 카운트 한 행렬이라는 전체적인 통계 정보를 입력으로 받아 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내는 방법론 | 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반의 방법론 |
| 한계 | 같은 단어 의미의 유추 작업(Analogy task)에는 성능이 떨어짐 | 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못함 |
3. 그 외에도 페이스북에서 개발한 FastText은 Word2Vec는 단어를 쪼개질 수 없는 단위로 생각한다면, FastText는 하나의 단어 안에도 여러 단어들이 존재하는 것으로 간주합니다.
4. 사전 훈련된 워드 임베딩(pre-trained word embedding)은 가져와서 사용하는 케이스가 있는데 자연어 처리를 하려고 할 때 갖고 있는 훈련 데이터의 단어들을 임베딩 층(embedding layer)을 구현하여 임베딩 벡터로 학습하는 경우가 있습니다. 케라스에서는 이를 Embedding()이라는 도구를 사용하여 구현합니다. 위키피디아 등과 같은 방대한 코퍼스를 가지고 Word2vec, FastText, GloVe 등을 통해서 미리 훈련된 임베딩 벡터를 불러오는 방법을 사용하는 경우도 있습니다.
5. ELMo(Embeddings from Language Model)는 2018년에 제안된 새로운 워드 임베딩 방법론으로 가장 큰 특징은 사전 훈련된 언어 모델(Pre-trained language model)을 사용한다는 점입니다. 워드 임베딩 시 문맥을 고려해서 임베딩을 하겠다는 아이디어가 문맥을 반영한 워드 임베딩(Contextualized Word Embedding) 입니다.
출처 : https://wikidocs.net/50739
09-03 영어/한국어 Word2Vec 실습
gensim 패키지에서 제공하는 이미 구현된 Word2Vec을 사용하여 영어와 한국어 데이터를 학습합니다. ## 1. 영어 Word2Vec 만들기 파이썬의 gensim 패키지…
wikidocs.net
'머신러닝 & 딥러닝 > NLP(자연어 처리)' 카테고리의 다른 글
| [NLP] Recall / Precision / F1-score and AP(Average Precision) or AUC(Area Under the Curve)에 정의와 예시 (0) | 2023.08.26 |
|---|---|
| [NLP] 일본어 자연어 처리할 때 주의해야 할 점과 사용하는 도구 (1) | 2023.08.22 |
| [NLP] 한국어 경진 대회 Tip(Kospeech) (0) | 2023.05.16 |
| [NLP] Deep Speech2 분석하기(Kospeech) (0) | 2023.05.15 |
| [NLP] 한국어 자연어 처리 관점에서 RNN이란? (0) | 2023.05.15 |