작년 8월~9월까지 한국어 AI경진대회 네이버 CLOVER 부분에 본선에 진출을 하여 주요 영역별 회의 음성인식 성능향상을 위하여 모델을 개선을 하였습니다.
아래 포스트는 Kospeech 분석 및 대회를 위해서 어떤 개선사항이 있었는지 적어볼려고 합니다.
Kospeech란?
https://github.com/sooftware/kospeech
GitHub - sooftware/kospeech: Open-Source Toolkit for End-to-End Korean Automatic Speech Recognition leveraging PyTorch and Hydra
Open-Source Toolkit for End-to-End Korean Automatic Speech Recognition leveraging PyTorch and Hydra. - GitHub - sooftware/kospeech: Open-Source Toolkit for End-to-End Korean Automatic Speech Recogn...
github.com
Kospeech란 오픈 소스 소프트웨어는 딥 러닝 라이브러리 PyTorch를 기반으로 하는 모듈식 확장 가능한 종단 간 한국어 자동 음성 인식(ASR) 툴킷입니다. 여러 자동 음성 인식 오픈 소스 툴킷이 출시되었지만 모두 영어(예: ESPnet, 에스프레소)와 같은 비한국어 언어를 다루고 있습니다. KsponSpeech 말뭉치와 여러 모델(Deep Speech 2, LAS, Transformer, Jasper, Conformer)에 대한 전처리 방법을 제안합니다. 아래의 내용은 본선 진출해서 사용한 Deep Speech2 논문을 통하여 모델을 분석한 뒤 각 모델별로 어떤 성능차이가 있을지 파악해보도록 하겠습니다.
Deep Speech2란?
Deep Speech2는 End-To-End 딥 러닝 시스템이므로 세 가지 중요한 구성 요소인 모델 아키텍처, 레이블이 지정된
대형 교육 데이터 세트 및 계산 규모에 집중하여 성능 향상을 달성할 수 있습니다.
논문 : https://arxiv.org/abs/1512.02595
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learni
arxiv.org
Model Architechture
단일 반복 레이어가 있는 단순한 다중 레이어 모델은 수천 시간의 레이블이 지정된 음성을 사용할 수 없습니다. 이렇게 큰 데이터 세트에서 학습하기 위해 깊이를 통해 모델 용량을 늘립니다.
많은 recurrent layer와 convolutional layer를 포함하여 최대 11개의 레이어가 있는 아키텍처를 탐색합니다. 이러한 모델은 Deep
Speech 1의 모델보다 데이터 예제당 거의 8배의 계산량을 가지고 있어 빠른 최적화 및 계산이 중요합니다. 따라서 이러한 모델을 성공적으로 최적화하기 위해 RNN용 Batch Normalization와 SortaGrad라는 새로운 최적화 커리큘럼을 사용합니다. 이것으로 RNN 입력 사이의 긴 보폭 을 활용하여 예제당 계산을 3배로 줄입니다.
이것은 훈련과 평가 모두에 도움이 되지만 CTC와 잘 작동하려면 약간의 수정이 필요합니다. 마지막으로, 많은 연구 결과가 bidirectional recurrent layers를 사용하지만 unidirectional recurrent layers만 사용하는 우수한 모델이 존재한다는 사실을 발견했습니다.
Preliminaries
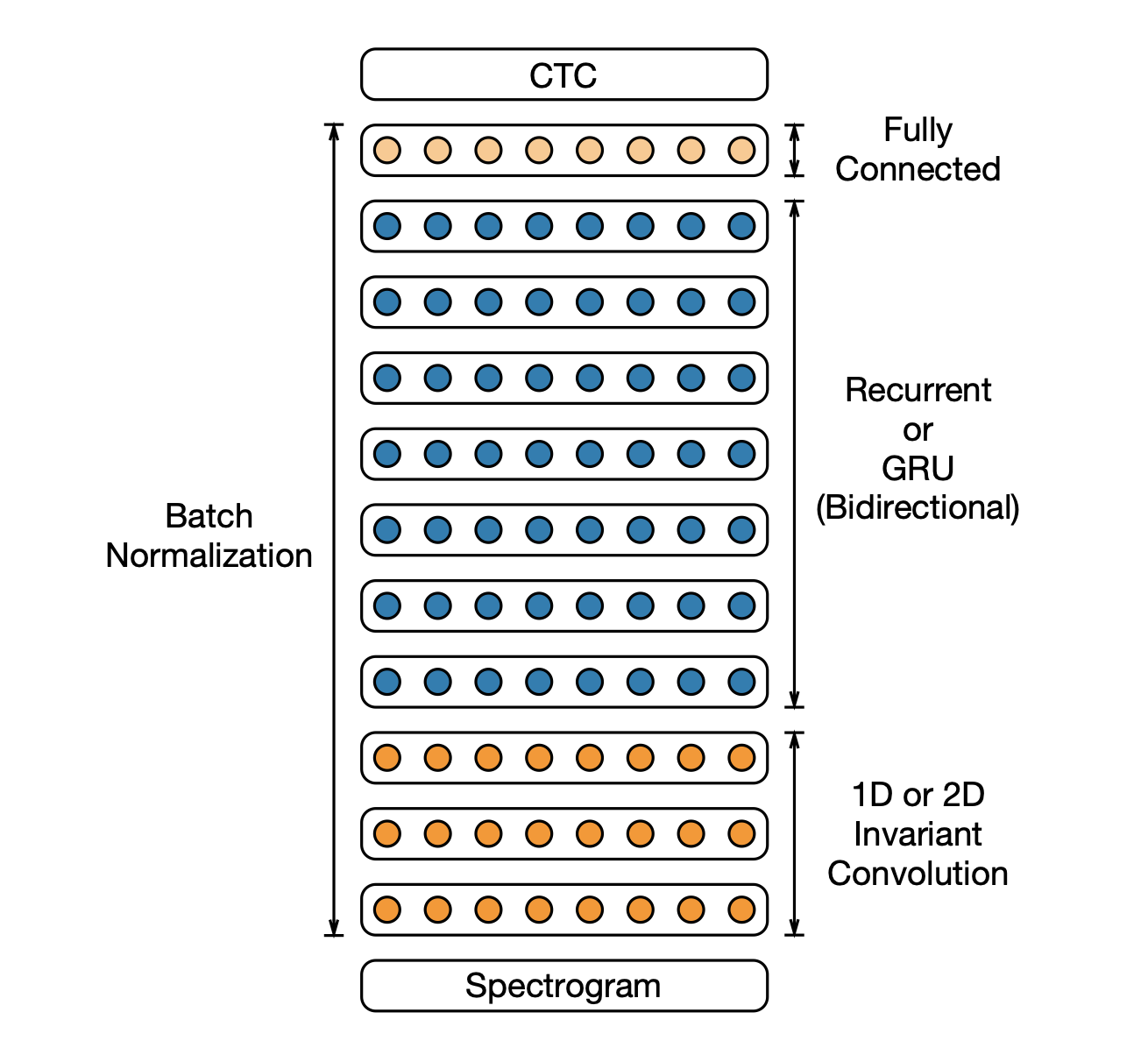
그림에서는 이전 DS1 시스템과 유사한 DS2 시스템의 아키텍처를 보여줍니다. 참고로 DS1은 음성 스펙트로그램을 수집하고 텍스트 전사를 생성하도록 훈련된 순환 신경망(RNN)입니다.
training set은 X = {(x(1), y(1)), (x(2), y(2)), . . .}.(x = single utterance, y = label) 형태로 구성이 되어있습니다. 여기서 네트워크의 출력은 각 언어의 문자소입니다. 각 출력 시간 단계 t에서 RNN은 문자 p(t|x)에 대한 예측을 수행합니다. 영어에서는 t ∈ {a, b, c, . . . , z,space,apostrophe,blank}로 구성이 되어있고 여기서 단어 경계를 나타내기 위해 아포스트로피와 공백 기호를 추가했습니다.
레이어 l의 은닉 표현은 h로 주어지며 입력 x를 나타냅니다. 크기가 c인 컨텍스트 윈도우의 경우 컨벌루션 계층의 시간 단계 t에서 i번째 활성화는 다음과 같이 지정됩니다.
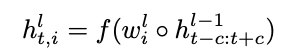
여기서 ◦는 i번째 필터와 이전 레이어 활성화의 컨텍스트 창 간의 요소별 곱을 나타내고 f는 단항 비선형 함수를 나타냅니다. 클립 정류
선형(ReLU) 함수 σ(x) = min{max{x, 0}, 20}을 비선형성으로 사용합니다. 일부 레이어, 일반적으로 첫 번째 레이어에서는 s 프레임으
로 컨벌루션을 스트라이드하여 하위 샘플링합니다. 목표는 위의 반복 레이어에 대한 시간 단계 수를 줄이는 것입니다.
컨볼루션 레이어 다음에는 하나 이상의 양방향 반복 레이어가 있습니다. 앞의 시간을 h->l, 뒤에 시간을 h<-l인 반복 레이어 활성화는 다음과 같이 계산됩니다.
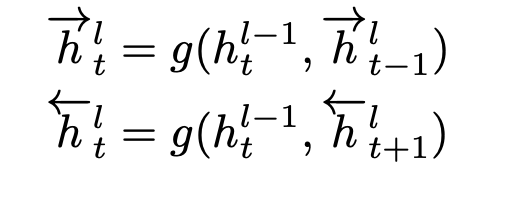
그러면 이제 첫번째 그림에서 영어와 북경어 음성 교육에 사용되는 DS2 시스템의 아키텍처. 컨볼루션 레이어의 수를 1에서 3으로, 순환 또는 GRU 레이어의 수를 1에서 7로 변경하여 이 아키텍처의 변형을 탐색합니다.
두 세트의 활성화는 합산되어 레이어 hl = h->l + h<-l에 대한 출력 활성화를 형성합니다.함수 g(·)는 표준 반복 연산이 될 수 있습니다.

bidirectional recurrent layers 후에 다음과 같은 하나 이상의 connected layers를 적용합니다.
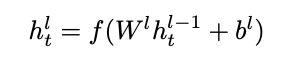
출력 레이어 L은 다음과 같이 주어진 문자에 대한 확률 분포를 계산하는 소프트맥스입니다.
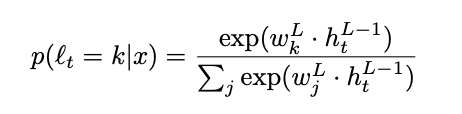
마지막으로 우리는 영어 시스템에 대한 단어 오류율(WER)과 만다린 시스템에 대한 문자 오류율(CER)는 아래와 같습니다.
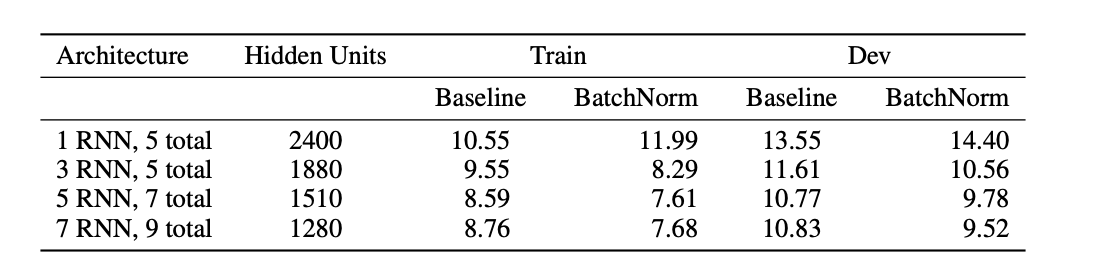
Batch Normalization for Deep RNNs
훈련 세트를 확장할 때 모델을 효율적으로 확장하기 위해 각 계층을 더 크게 만드는 대신 숨겨진 계층을 추가하여 네트워크의 깊이를 늘립니
다. 이때최적화 문제가 자주 발생하기 때문에 이러한 네트워크에 대한 학습을 가속화하는 기술로 Batch Normalization(BatchNorm)을 살펴봅니다.
비선형 f(·)가 뒤따르는 affine transformation을 포함하는 일반적인 feed-forward layer에서 f(W h + b) 대신 f(B(W h))를 적용하여 BatchNorm 변환을 삽입합니다. 아래에서 Var: 분산 E: 평균 r, b : learnable parameters입니다.
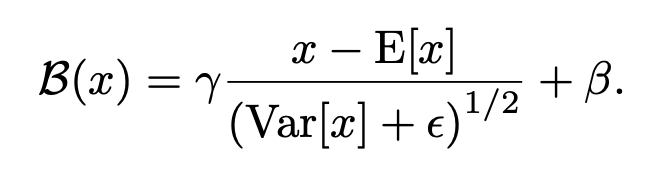
기존의 batch normalization인 미니 배치의 single time-step에 걸친 축적은 효과가 없다고 합니다.
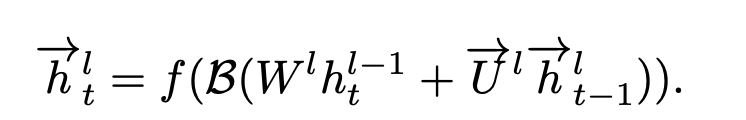
우리는 sequence-wise normalization[37]이 이러한 문제를 극복한다는 것을 발견했습니다. 반복 계산은 다음과 같이 지정됩니다.

아래의 그림에서는 심층 네트워크가 시퀀스별 정규화로 더 빠르게 수렴됨을 보여줍니다.
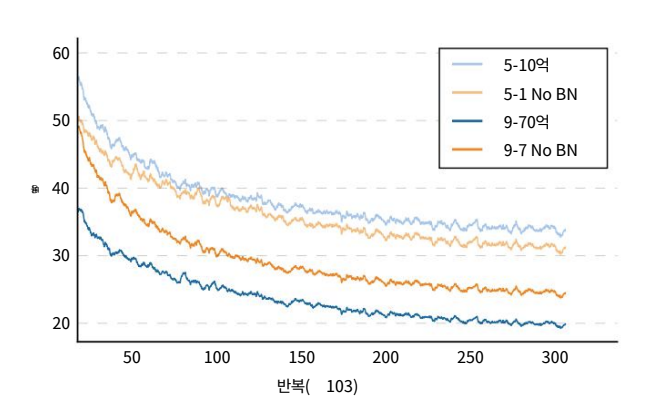
따라서 매개변수의 수를 늘리고 여전히 강력한 성능 향상을 볼 수 있습니다. 레이어당 활성화 수를 일정하게 유지하고 레이어를 추가하면 깊이에서 훨씬 더 큰 개선을 기대할 수 있습니다. 또한 BatchNorm이 더 얕은 네트워크에 대해 더 느리게 수렴하는 것처럼 가장 얕은 네트워크에 대한 일반화 오류에 해를 끼친다는 것을 발견했습니다.
바로 training에서는 학습이 잘되지만 sigle utterance만 들어가는 ASR시스템에서 결과가 좋지 못하다는 것입니다. 그래서 여기에서는 각각의 뉴런을 normalize하는 방법을 사용한다고 합니다.(train동안 수집된 뉴련의 (평균과 분산)의 평균을 저장)
SortaGrad
다양한 길이의 예제에 대한 교육에는 몇 가지 알고리즘 문제가 있습니다. 한 가지 가능한 해결책은 시간을 통해 역전파를 자르는 것입니다
간단히 얘기하자면 어려운(긴 거) 먼저 학습시키자! 라는 방법입니다.
- 첫번째 에폭에서 미니 배치 안에서 작은순서에서 긴 순서대로 배치하여서 학습시킨다.
- 첫번째 에폭이 끝나면 다시 랜덤학습으로 돌아간다
특히 SortaGrads는 batch norm이 없는 네트워크에서 numerically 덜 안정하기 때문에 좋은 결과를 낸다고 합니다.
우리는 이러한 이점이 주로 긴 발화의 기울기가 더 큰 경향이 있기 때문에 발생한다고 생각하지만 발화 길이와 관계없이 고정된 학습 속도
를 사용합니다. 또한 더 긴 발언은 훈련 초기 단계에서 RNN의 내부 상태를 폭발시킬 가능성이 더 큽니다.
Comparison of simple RNNs and GRUs
음성 및 언어 처리에 대한 현재 연구에 따르면 더 복잡한 반복을 사용하면 네트워크가 더 많은 시간 단계에 걸쳐 상태를 기억할 수 있지만
훈련하는 데 계산 비용이 더 많이 듭니다. 일반적으로 사용되는 두 가지 반복 아키텍처는 LSTM(Long Short-TermMemory) 장치와 Gated Recurrent Units(GRU)이지만 다른 변형도 많이 있습니다.
최근 연구에 따르면 GRU는 적절하게 초기화된 게이트 게이트 바이어스가 있는 LSTM과 유사하며 최상의 변형은 서로 경쟁적입니다. 더 작은 데이터 세트에 대한 실험에서 GRU와 LSTM이 동일한 수의 매개변수에 대해 비슷한 정확도에 도달하는 것으로 나타났기 때문에 GRU를 조사하기로 결정했지만 GRU는 학습 속도가 더 빠르고 분기 가능성이 적습니다.
GRU와 간단한 RNN 아키텍처 모두 배치 정규화의 이점을 누리고 심층 네트워크에서 강력한 결과를 보여줍니다. 그러나 아래의 표에서 고정된 수의 매개변수에 대해 GRU 아키텍처가 모든 네트워크 깊이에 대해 더 나은 WER을 달성한다는 것을 보여줍니다. 이것은 음성 인식 작업에 내재된 장기 의존성이 개별 단어와 음성 인식 모두에 존재한다는 분명한 증거입니다.
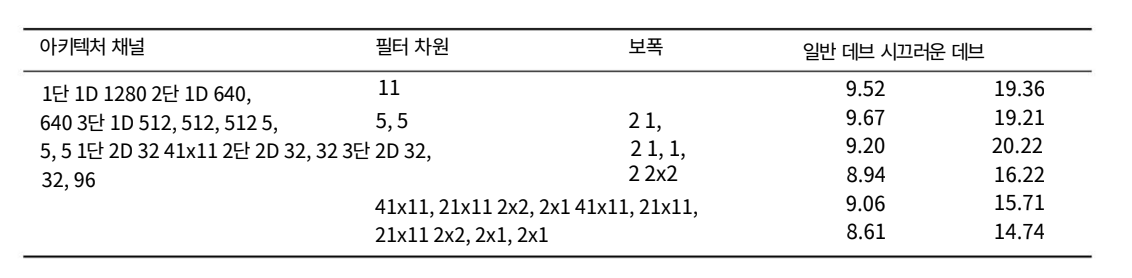
간단한 RNN도 많은 양의 훈련 데이터로 인해 언어 모델을 암묵적으로 학습할 수 있습니다. 그리고 5개 이상의 recurrent 레이어가 있는 GRU 네트워크는 성능을 크게 향상시키지 않습니다. 총 매개변수 수를 일정하게 유지하기위해 1개의 반복 레이어에 대한 레이어당 1728개의 숨겨진 유닛에서 7개의 반복 레이어에 대한 레이어당 768개의 숨겨진 유닛으로 얇아지기 때문입니다.
하지만 fixed computational budget을 위해 모델을 키울때 simple RNN network가 좀더 좋은 성능을 내는것을 확인할 수 있었다고 합니다.
Frequency Convolutions
기존의 음성파일은 길이가 길고 잡음도 섞여 있기 때문에 모든 스펙토그램을 그대로 쓰는것은 좋지 못하다고 판단하고 앞단에 Convolution 층을 추가해 다음과 같은 문제를 해결했다고 합니다.
또한 2D Convolution과 1D Convolution을 테스트 해본 결과 1D Convolution은 아주 조금의 성능향상이 있었고 2D Convolution은 특히 소음이 많은 환경에서 큰 성능 향상을 제공하였다고 합니다.
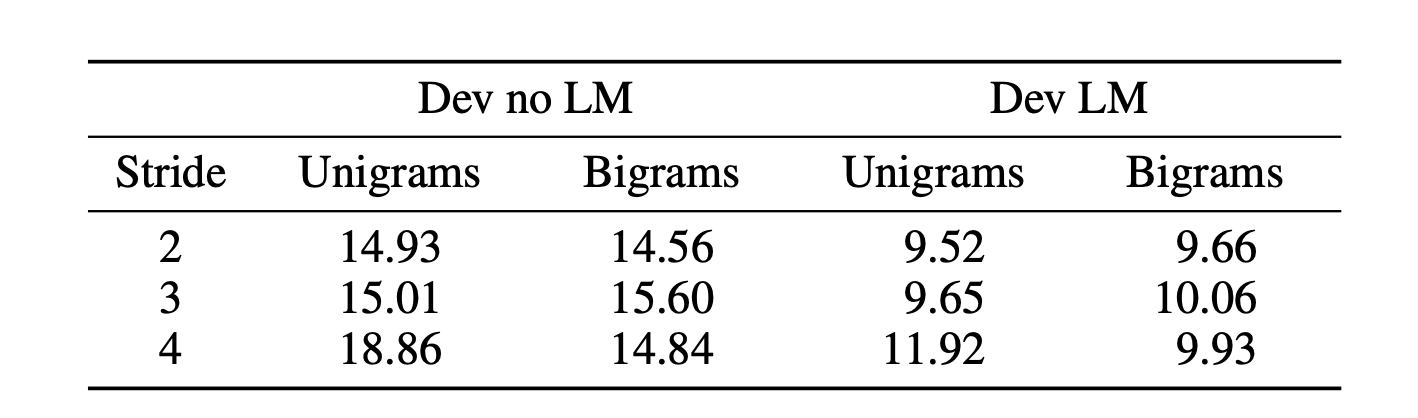
Striding
컨볼루션 레이어에서는 주어진 발화를 모델링하는 데 더 적은 시간 단계가 필요하므로 더 긴 보폭과 더 넓은 컨텍스트를 적용하여 학습 속도
를 높입니다. 입력 사운드를 다운샘플링(FFT 및 컨벌루션 스트라이드를 통해)하면 다음 레이어에 필요한 시간 단계 및 계산 수가 줄어들지만 성능이 저하됩니다.
본 논문에서는 영어는 단순히 우리 네트워크의 출력이 출력 문자당 적어도 하나의 time-step을 필요로 하고, 타임스텝당 영어 음성의 문자 수가 striding을 할때 문제를 일으킬 만큼 충분히 높기 때문에 striding은 정확도를 떨어뜨릴 수 있습니다. 이것을 극복하기 위해서 labelling함으로써 단순한 알파벳뿐만 아니라 [th, e, space, ca, t, space, sa, t] 다음과 같이 라벨링을 하여서 사용합니다.
Row Convolution and Unidirectional Models
Bidirectional RNN은 모든 값들이 들어가야함으로 online이나 low-latency를 요구하는 환경에서는 사용을 할 수 없는데 이 논문에서는 이러한 문제를 해결하기 위해서 단방향 새로운 단방향 구조를 제안했습니다.
새로운 단 방향 구조는 row convolution이라고 합니다. row convolution은 time-step에서 정확한 예측을 하기 위해서 미래 정보에서 일부분만 있으면 된다는 가정을 하고 고안되었다고 합니다.

Language Model
우리는 네트워크가 강력한 암시적 언어 모델을 학습할 수 있도록 하는 수백만 개의 고유 발화에 대해 RNN 모델을 교육합니다.
최고의 모델은 외부 언어 제약 없이 맞춤법에 매우 능숙합니다. 또한 개발 데이터 세트에서 모델이 암시적으로 동음이의어를 명
확하게 할 수 있는 많은 경우를 발견했습니다. 그럼에도 불구하고 레이블이 지정된 학습 데이터는 사용 가능한 레이블이 지정되
지 않은 텍스트 말뭉치의 크기에 비해 작습니다. 따라서 우리는 외부 텍스트에서 훈련된 언어 모델로 시스템을 보완할 때 WER
이 향상된다는 것을 발견했습니다.

5개 레이어와 1개의 반복 레이어가 있는 모델에서 9개 레이어와 7개의 반복 레이어가 있는 모델로 이동함에 따라 언어 모델에 의해 제공되는상대적 개선은 영어의 경우 48%에서 36%로, 북경어의 경우 27%에서 23%로 떨어집니다.
Adaptation to Mandarin
(Mandarin부분은 생략하겠습니다.)
Training Data
본 논문에서는 사용 가능한 데이터 세트로 교육을 강화하는 것 외에도 영어 및 북경어 음성 모델에 대한 광범위한 교육 데이터 세트를 수집했습니다.
Dataset Construction
일부 내부 영어(3,600시간) 및 북경어(1,400시간) 데이터 세트는 시끄러운 필사본이 포함된 긴 오디오 클립으로 캡처된 원시 데이터에서 생성되었습니다. 이 클립의 길이는 몇 분에서 몇 시간 이상에 이르기 때문에 훈련 중에 RNN에서 제 시간에 풀기가 비실용적입니다. 이 문제를 해결하기 위해 우리는 더 짧은 발화와 오류가 거의 없는 훈련 세트를 생성할 수 있는 정렬, 세분화 및 필터링 파이프라인을 개발했습니다.
파이프라인의 첫 번째 단계는 CTC로 훈련된 기존 양방향 RNN 모델을 사용하여 전사를 오디오 프레임에 맞추는 것입니다. 주어진 오디오 대본 쌍(x, y)에 대해 다음을 최대화하는 정렬을 찾습니다.
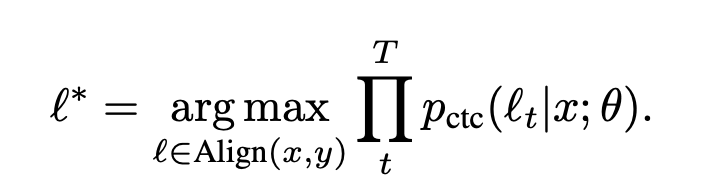
audio-transcript pair가 (x, y) 다음과 같은 pair할때 다음과 같이 maximize되는것을 확인할 수 있는데 이것은 근본적으로 CTC로 훈련된 RNN 모델을 사용한 Viterbi alignment라고 합니다. 원래 CTC는 어느정도의 지연 후에 모든 문자를 방출하는데 이런 경우는 unidirectional RNN에서 발생한다고 합니다. 하지만 bidiriectional RNN은 정확한 alignment를 만들어 내는것을 알아냈다고 합니다.
파이프라인의 마지막 단계는 실패한 정렬에서 발생하는 잘못된 예를 제거합니다. 우리는 수천 가지 예에 대한 실측 기록을 넘치게 가지고 있습니다. Ground Truth와 정렬된 전사 사이의 단어 수준 편집 거리는 양호 또는 불량 라벨을 생성하는 데 사용됩니다.
Data Argumentation
노이즈를 추가하여서 훈련 데이터의 크기를 증가시켰다고 합니다. 하지만 너무 많은 소음의 증가는 최적화를 어렵게 하고 더 나쁜 결과를 초래할 수 있어 무작위로 선택된 발화의 40%에 노이즈를 추가하는 것이 좋은 균형이라는 것을 알았습니다. 노이즈 소스는 수백 시간의 노이즈를 생성하기 위해 결합된 수천 시간의 무작위로 선택된 오디오 클립으로 구성됩니다.
Scaling Data
원시 시간을 늘리는 것 만큼이나 중요한 것이 Data 양을 증가 시키면 더욱 WER이 줄어드는것을 확인 할 수 있다고 합니다. 특히 데이터를 수집할때 다양한 스피커, 배경잡음 , 환경 및 마이크 하드웨어를 포함하여 여러자지의 음성 컨텍스트의 수를 늘리는것 또한 좋은 결과를 얻을수 있을것이라고 논문에 나와있습니다.
Results
본 논문에서는 실제 적용 가능성을 확인하기 위해 테스트 세트는 낮은 신호 대 잡음비(잡음 및 원거리), 악센트, 읽기, 자발적 및 대화 음성을 포함하여 광범위한 도전적인 음성 환경을 나타내는 내부 데이터셋과 외부 데이터 셋을 사용했다고 합니다.
- hyperparameter
-학습 epoch : 20
-optimizer : stochastic gradient descent with Nesterov momentum (momentum 0.99) -minibatch size : 512
-learning rate : [1x10^-4, 6x10^-4] annealed by a constant factor of 1.2 after each epoch
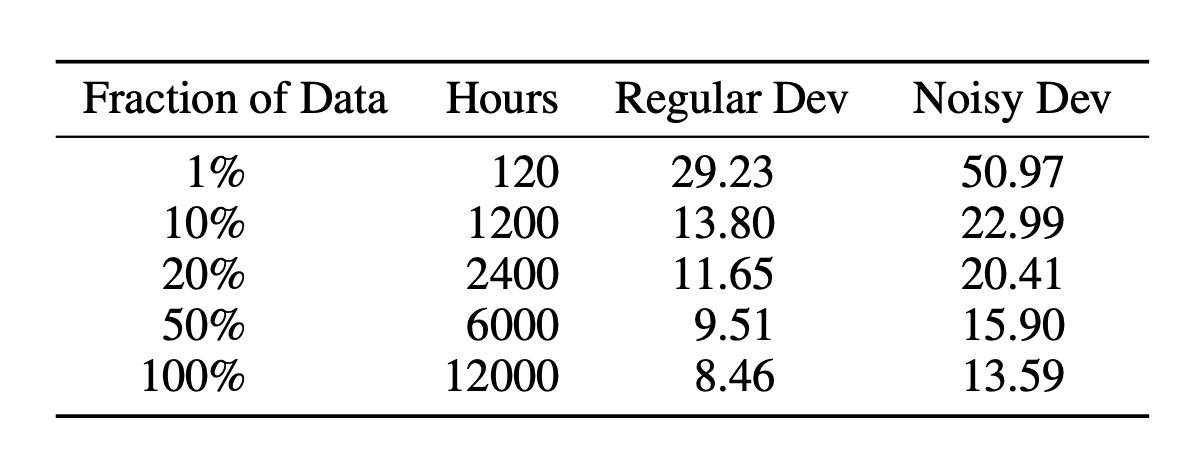
English
실험 결과 최상의 결과를 내는 DS2 모델은 3개의 2D convolution layer 와 7개의 rnn layer, batch normalization과 함께 1개의 fully-connected layer, 총 11개의 layer로 구성되어있다고 합니다. 기존 ground truth 기록에는 약간의 레이블 오류가 있지만 1%를 넘는 경우는 거의 없습니다. 이것은 직접 사람의 인식 수준과 비교해 보았을때 거의 인간 수준의 성과를 낸다고 합니다.
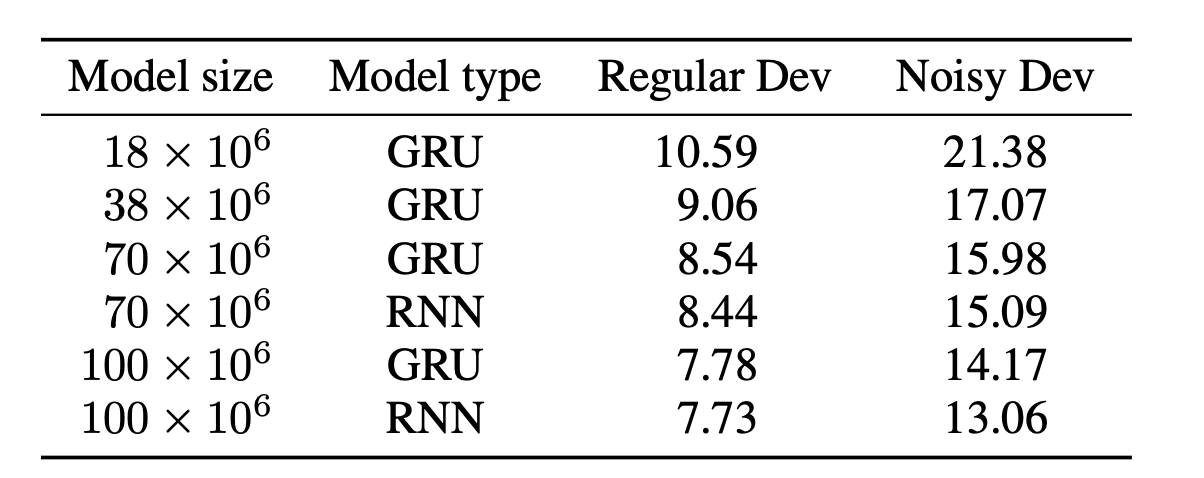
당연하게도 파라미터의 개수 즉 모델 사이즈를 크게 하면 할수록 효과가 좋게 나오는것을 확인 할 수 있습니다. 또한, 앞에서 언급한대로 파라미터의 값을 최대 1억개이상으로 늘리면 GRU보다 simple RNN이 조금이지만 더 나은 성능을 발휘하고 속도도 좀더 빠르다고 합니다. (stride는 3, bigram으로 출력)
Read Speech, Accented Speech, Noisy Speech
본 논문에서는 모델의 실제 적용성을 확인하기 위해서 여러 데이터 셋을 이용하여 확인하였다고 합니다.
- Read Speech test set - 4개의 테스트 세트 중 3개 테스트 세트에서 인간을 능가한다고 합니다.
- Accented Speech - 억양차이를 가지는 테스트 세트인데 인도억양을 제외한 모든 데이터 셋인데 DS1보다 좋은 결과를 냈다고 합니다.
- Noisy Speech - 노이즈가 없을 때의 성능은 인간을 능가하지만 노이즈가 많이 있을 때는 인간보다 성능이 낮게 나오는것을 확인할 수 있다고 합니다.
Conclusion
End-to-End 딥 러닝은 데이터 및 계산이 증가함에 따라 음성 인식 시스템을 지속적으로 개선할 수 있는 흥미로운 기회를 제공합니다. 실제로, 우리의 결과는 이전 화신과 비교하여 Deep Speech가 더 많은 데이터와 더 큰 모델을 활용하여 인간 작업자와의 전사 성능 격차를 크게 좁혔다는 것을 보여줍니다. 또한 접근 방식이 매우 일반적이기 때문에 새로운 언어에 빠르게 적용할 수 있음을 보여주었습니다.
'머신러닝 & 딥러닝 > NLP(자연어 처리)' 카테고리의 다른 글
| [NLP] 워드 임베딩(Word Embedding) (0) | 2023.05.16 |
|---|---|
| [NLP] 한국어 경진 대회 Tip(Kospeech) (0) | 2023.05.16 |
| [NLP] 한국어 자연어 처리 관점에서 RNN이란? (0) | 2023.05.15 |
| [NLP] 한국어 텍스트 전처리 과정(2) (1) | 2023.05.12 |
| [NLP] 한국어 텍스트 전처리 과정(1) (2) | 2023.05.12 |