https://arxiv.org/abs/2309.11674
A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. However, these advances have not been reflected in the translation task, especially those with moderate model sizes (i.e., 7B or 13B parameters), which stil
arxiv.org
첫 번째 논문으로 위에 제목은 기계 번역의 패러다임 전환: 대규모 언어 모델의 번역 성능 향상(ALMA)입니다.
위에서 저자들은 패러다임 전환으로 거창한 이유를 적어 놓았는데 그 이유를 알아 보도록 하겠습니다.
기존의 번역 모델은 인코더용 트랜스포머와 디코더용 트랜스포머가 같이 존재하는 것을 사용해 왔습니다.
그러나 GPT이후 ICL을 통해 분류나 번역 같은 임무를 수행할 수 있다는 것이 확인되었습니다. 그러나 모델 용량 대비
디코어와 인코더를 모두 가지는 것에 비해서 성능이 많이 떨어졌습니다. 단적인 예로 OPT-175B 모델 은 인도-유럽 언어군에서 NLLB-1.3B 모델에 비해 평균 15 BLEU 점 이상 뒤처지며, 더 작은 LLMs의 경우 차이는 더욱 큽니다. 그리고
7B 파라미터의 XGLM은 NLLB-1.3B에 비해 30 BLEU 점 이상 뒤처집니다.
전통적인 기계 번역 모델은 적은 수의 파라미터로 고품질 번역을 생산하는 능력을 보여줍니다. 따라서 LLMs와 전통적인 최신 모델 간의 성능 격차를 좁힐 필요합니다.
요즘의 LLM 연구는 주로 디코더만 달린 모델들 중심으로 투자와 연구가 이루어지고 있고, 디코더 모델로 번역을 좀 더 잘 할 수 없을까라는 관점에서 연구를 하게 되었습니다.
이제 ALMA 에서 제시하는 방법론을 살펴봅시다. 논문의 저자들이 제시한 해결방법은 학습을 2단계로 실시하는 것입니다.
1. 보통 모델들은 영어로만 트레이닝 되어 있으니까, 일단 대상 언어 자체의 능력을 향상하기 위한 추가 학습을 실시한다
예를 들어, 영어로만 학습된 솔라에서, 한국어 토큰을 많이 학습시킨 야놀자 모델로 파인튜닝하는 것입니다.
2. 두번째 단계는 높은 퀄리티로 엄선된 원문-번역문 쌍 데이터를 추가학습시킨다
여기서 포인트는 본격적인 번역문 학습은 양보다 질이 중요하다는 점입니다. 기존에는 3억건 (300M)이 넘는 데이타를 학습시켜봤지만 번역성능이 점점 좋아지지는 않고 어느 시점부터는 오히려 성능이 떨어지더라는 것입니다.

이후 논문의 내용은 성능의 비교에 대한 것들이고, 저자들이 가정했던 사항들 (1. 대상 언어에 대한 선 학습이 중요하다. 2. 원문-번역문 쌍에 대한 학습은 너무 많을 필요 없다) 에 대한 정량적 비교 분석으로 주를 이루고 있습니다.
결론적으로 언어 번역기를 만들고 싶은 사람에게 주는 메시지가 있다면 양질의 데이터셋을 만드는데 주력하자. 무조건 많이 모으는 것보다는 데이타셋의 질이 좋아지도록 필터링을 잘 해서 비슷비슷한 내용들은 빼버리고, 꼼꼼하게 검수를 해서 틀린 번역이 데이타셋에 들어가지 않도록 하자 입니다.
따라서 전문 영역(게임, 의료, 법률 등)에 맞는 데이터셋을 모을려면 그에 맞는 전문 영역 데이터셋을 구축하고 그와 동시에 중복 및 퀄리티면에서 체크를 실시해야 될 것입니다.
https://arxiv.org/abs/2401.08417
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation
Moderate-sized large language models (LLMs) -- those with 7B or 13B parameters -- exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation models, like ALMA, does not match the performance of state-
arxiv.org
두번째 논문으로 저자들은 ALMA 위에 강화학습 개념을 적용한 ALMA-R 이라는 논문을 발표했습니다.
기계 번역(MT)은 주로 변환기 인코더-디코더 아키텍처를 사용하며, NLLB-200, M2M100, BIBERT, MT5와 같은 주요 모델에서 이를 볼 수 있습니다. 그러나 GPT 시리즈, Mistral, LLaMA, Falcon 등의 디코더 전용 대규모 언어 모델(LLM)의 등장은 다양한 자연어 처리(NLP) 작업에서 뛰어난 효율성을 보여줌으로써 이러한 디코더 전용 LLM을 이용한 기계 번역 개발에 관심을 불러일으켰습니다. 최근 연구에 따르면 GPT-3.5와 GPT-4와 같은 더 큰 LLM은 강력한 번역 능력을 보여주지만, 크기가 작은 LLM(7B 또는 13B)은 전통적인 번역 모델에 비해 성능이 떨어집니다. 따라서, 이러한 작은 LLM의 번역 성능을 향상시키기 위한 연구가 진행되고 있으나, LLM이 주로 영어 중심의 데이터셋에 대해 사전 훈련되어 있어 언어 다양성이 제한되어 있기 때문에 개선 효과는 상대적으로 제한적입니다.
이러한 제한을 해결하기 위해 LLaMA-2를 대량의 비영어 단일 언어 데이터로 미세 조정한 후 고품질 병렬 데이터로 감독된 미세 조정을 수행하여 모델이 번역을 생성하도록 지시하여, ALMA라는 모델을 개발했습니다. ALMA는 기존의 중간 크기 LLM과 심지어 GPT-3.5보다 번역 작업에서 우수한 성능을 보였지만, GPT-4 및 WMT 경쟁 우승자와 같은 선도적인 번역 모델에 비해 여전히 성능이 뒤쳐집니다. 우리 연구는 ALMA 모델을 Contrastive Preference Optimization(CPO)이라는 새로운 훈련 방법으로 더욱 미세 조정하여 성능을 향상시켰고, ALMA-R이라는 미세 조정된 모델은 GPT-4 및 WMT 경쟁 우승자와 같거나 그보다 뛰어난 성능을 보였습니다.
CPO의 핵심 개념은 아래와 같습니다.
Constrative 라는 단어가 붙은 것을 보면 알 수 있는 점은 뭔가의 차이점을 대조해서 거기에서 학습을 유도한다는 점입니다. 기존의 방법은 별도의 보상모델이나 자체 모델이 점수를 뽑아내게 해서 loss 에 참고하는 방식이었는데, CPO 에서는 3개의 문장을 갖고 외부모델이 점수를 매겨서 loss 를 계산하는 식으로 합니다.
아래의 3 개의 문장은 각각 비교를 실시합니다.
1. 번역 데이타셋에 들어있는 정답 번역문 (ref)
2. GPT-4 가 번역한 문장 (gpt4)
3. 자체 모델이 번역한 문장 (alma)
거기에 평가전용 모델 (KIWI-XXL 과 XCOMET) 을 이용해서 각 문장들의 점수를 매기게 됩니다.
추가적으로 XCOMET 논문과 코드는 아래 링크를 남겨둡니다.
https://github.com/Unbabel/COMET?tab=readme-ov-file
GitHub - Unbabel/COMET: A Neural Framework for MT Evaluation
A Neural Framework for MT Evaluation. Contribute to Unbabel/COMET development by creating an account on GitHub.
github.com
https://arxiv.org/abs/2310.10482
xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection
Widely used learned metrics for machine translation evaluation, such as COMET and BLEURT, estimate the quality of a translation hypothesis by providing a single sentence-level score. As such, they offer little insight into translation errors (e.g., what ar
arxiv.org

이렇게 3개의 점수를 갖게 되면, 자체모델보다 높은 모델에 대해서는 더 따라가는 쪽으로의 학습을 하고, 더 낮게 나온 경우에 대해서는 멀어지는 쪽으로 학습하게 되는 것이 CPO 의 기본적인 작동입니다. DPO 와 가장 다른 점은 메모리와 속도의 낭비를 막기 위해서 불필요한 계산 단계를 줄이는 것입니다.
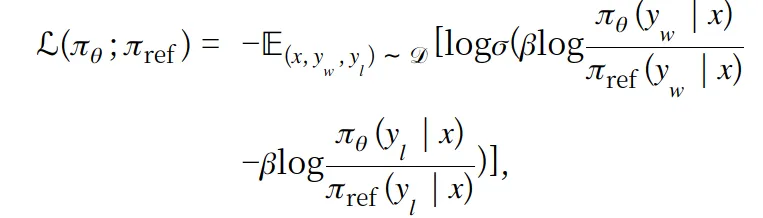
위는 DPO 수식인데 주목해야 할 점은 π로 적혀진 부분이 있는데 이 때 모델에 한번 추론을 돌리는 계산을 실시합니다.
따라서, x 라는 데이타 한개에 대한 loss 를 계산하기 위해서 모델의 추론을 4번이나 돌린다는 점입니다.
논문의 저자들이 제시하는 CPO에서의 loss 수식은 아래와 같습니다.
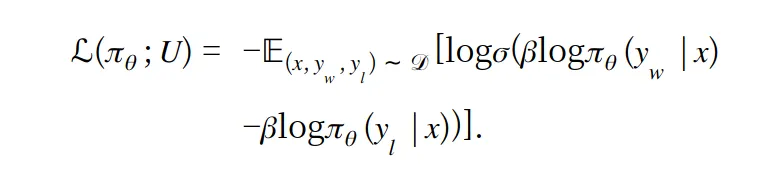
계산을 근사치로 잘 하고 로그 연산을 통해 두개의 항을 소거시켜서 모델의 추론 연산을 4번에서 2번으로 줄였다는 것이 핵심입니다. 그러므로 무거운 추론 연산을 반으로 줄였으니 상당한 발전이고 그에 따라 성능이 올라가니 추후에 번역기 및 다른 데이터셋을 구성하는 과정에서도 이를 유의하면서 구성하면 성능의 발전이 보입니다.
추가적으로 ALMA의 코드 링크를 남기고 이만 리뷰를 마치겠습니다.
https://github.com/fe1ixxu/ALMA
GitHub - fe1ixxu/ALMA: This is repository for ALMA translation models.
This is repository for ALMA translation models. Contribute to fe1ixxu/ALMA development by creating an account on GitHub.
github.com
'논문 리뷰 > Language Model' 카테고리의 다른 글
| [논문 리뷰] WizardMath-70B-V1.0 논문 리뷰 (2) | 2024.04.19 |
|---|---|
| [논문 리뷰] MetaMath-70B-V1.0 논문 리뷰 (0) | 2024.04.19 |