현재 LLM에서 혁신적인 파일 형식이 등장하였는데 GGML과 GGUF를 소개하고자 합니다.
GGML 개요
GGML은 기계학습 분야에서 중요한 역할을 하는 텐서 라이브러리입니다. 이는 크기가 큰 모델과 다양한 하드웨어 환경에서 높은 성능을 발휘합니다.
장점
- GPT 모델용 파일 형식으로 처음 시도된 사례입니다.
- 하나의 파일로 모델을 쉽게 공유하는 것이 가능합니다.
- 다양한 사용자가 CPU에서도 GGML 파일 실행하는 것이 가능합니다.
단점
- 모델의 추가적인 정보를 입력하는 것이 어렵습니다.
- 새로운 기능 추가 시 기존 모델과의 호환 문제가 생깁니다.
- 사용자가 수동적으로 설정을 변경해야 하는 어려움이 있습니다.
GGML 유형
- GGML_TYPE_Q2_K - 16개의 블록을 포함하는 수퍼 블록의 "유형 1" 2비트 양자화, 각 블록은 16개의 가중치를 가집니다. 블록 스케일과 최소값은 4비트로 양자화됩니다. 이는 결국 가중치당 2.5625비트(bpw)를 효과적으로 사용하게 됩니다.
- GGML_TYPE_Q3_K - 각 블록에 16개의 가중치가 있는 16개의 블록을 포함하는 수퍼 블록의 "type-0" 3비트 양자화. 스케일은 6비트로 양자화됩니다. 이것은 3.4375bpw를 사용하게 됩니다.
- GGML_TYPE_Q4_K - 8개의 블록을 포함하는 수퍼 블록의 "유형 1" 4비트 양자화, 각 블록에는 32개의 가중치가 있습니다. 스케일과 최소값은 6비트로 양자화됩니다. 이것은 4.5bpw를 사용하여 끝납니다.
- GGML_TYPE_Q5_K - "유형 1" 5비트 양자화. GGML_TYPE_Q4_K와 동일한 슈퍼 블록 구조로 5.5bpw
- GGML_TYPE_Q6_K - "type-0" 6비트 양자화. 16개의 블록이 있는 슈퍼 블록, 각 블록에는 16개의 가중치가 있습니다. 스케일은 8비트로 양자화됩니다. 이것은 6.5625bpw를 사용하여 끝납니다.
- GGML_TYPE_Q8_K - "type-0" 8비트 양자화. 중간 결과를 양자화하는 데만 사용됩니다. 기존 Q8_0과의 차이점은 블록 크기가 256이라는 것입니다. 이 양자화 유형에 대해 모든 2-6비트 내적이 구현됩니다.
이는 다음과 같이 다양한 "양자화 혼합"을 정의하는 llama.cpp 양자화 유형을 통해 노출됩니다.
- LLAMA_FTYPE_MOSTLY_Q2_K -tention.vw 및 feed_forward.w2 텐서에는 GGML_TYPE_Q4_K를 사용하고 다른 텐서에는 GGML_TYPE_Q2_K를 사용합니다.
- LLAMA_FTYPE_MOSTLY_Q3_K_S - 모든 텐서에 GGML_TYPE_Q3_K 사용
- LLAMA_FTYPE_MOSTLY_Q3_K_M -tention.wv,tention.wo 및 feed_forward.w2 텐서에 GGML_TYPE_Q4_K를 사용하고 그렇지 않으면 GGML_TYPE_Q3_K를 사용합니다.
- LLAMA_FTYPE_MOSTLY_Q3_K_L -tention.wv,tention.wo 및 feed_forward.w2 텐서에 GGML_TYPE_Q5_K를 사용하고 그렇지 않으면 GGML_TYPE_Q3_K를 사용합니다.
- LLAMA_FTYPE_MOSTLY_Q4_K_S - 모든 텐서에 GGML_TYPE_Q4_K 사용
- LLAMA_FTYPE_MOSTLY_Q4_K_M -tention.wv 및 feed_forward.w2 텐서의 절반에 대해 GGML_TYPE_Q6_K를 사용하고 그렇지 않으면 GGML_TYPE_Q4_K를 사용합니다.
- LLAMA_FTYPE_MOSTLY_Q5_K_S - 모든 텐서에 GGML_TYPE_Q5_K 사용
- LLAMA_FTYPE_MOSTLY_Q5_K_M -tention.wv 및 feed_forward.w2 텐서의 절반에 대해 GGML_TYPE_Q6_K를 사용하고 그렇지 않으면 GGML_TYPE_Q5_K를 사용합니다.
- LLAMA_FTYPE_MOSTLY_Q6_K- 모든 텐서에 대해 6비트 양자화(GGML_TYPE_Q8_K) 사용
위에서 명시적으로 언급되지 않은 것은 이 PR을 사용하면 모든 양자화 변형이 output.weight 텐서에 6비트 양자화를 사용한다는 사실입니다. 이는 예를 들어 Q4_0의 perplexity를 7B에서 약 0.03만큼 낮춥니다.
유의사항, GGML 파일 유형은 언제든 변경이 될 수 있으므로 확인 필수!입니다.
GGUF 소개
GGUF는 2023년 8월에 나온 새로운 파일 형식인데 대형 모델 언어(LLM)에서 저장과 처리에 큰 발전을 이루었습니다.
- 새로운 기능을 추가하여도 기존 모델과의 호환성을 가집니다.
- 새로운 버전으로 전환이 용이합니다.
- Llama 모델을 포함하여 다양한 모델을 제공합니다.
GGUF 구조
llm에서 GGUF는 단일 파일이기 때문에 모델의 Weight 값과 메타데이터가 들어있는 Key-Value 형식으로 저장되어 있습니다.
여기서 다른 ML라이브러리와는 다르게 8-bit, 6-bit, 5-bit, 4-bit, 3-bit 그리고 2-bit 양자 텐서타입까지 지원을 하고 있습니다.(다만, 언제 업데이트 되는지는 모르기 때문에 항시 체크하는 것이 좋습니다.)
저는 주로 llama.cpp 를 자주 사용하는데 여기서는 다양한 모델들을 양자화 변환을 하여 GGUF 파일로 제공합니다.
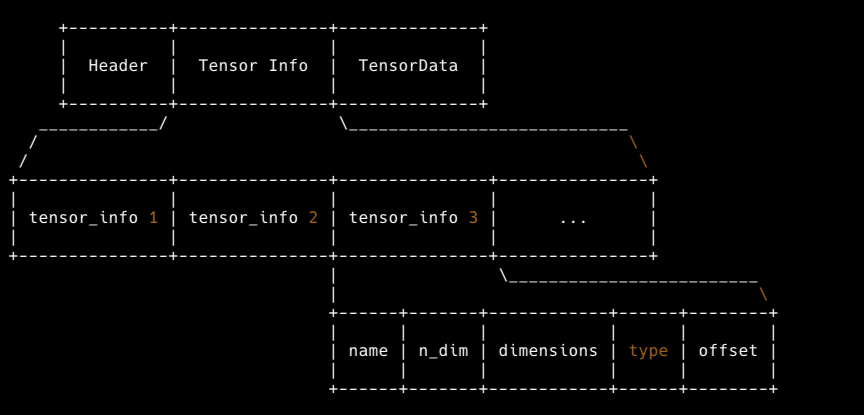
GGUF 파일에는 두 가지 정보가 기록되어 있습니다.
1. 모델의 Weight Tensor 값과 텐서 정보
- Tensor의 이름
- Tensor의 차원 수
- Tensor의 Shape
- Tensor의 데이터 타입
- Tensor 데이터가 위치한 Offset
2. Key-Value 형식의 메타데이터
Key는 ASCII 문자와 '.'으로 계층을 표시합니다.
예를 들어 llama.attention.head_count_kv로 표현이 가능합니다.
먼저 모델의 세부 정보들을 포함 시켜야 합니다.
- 입력 토큰 길이
- 임베딩 크기
- 피드 포워드 길이
여기에 더해서 Tokenizer 정보도 포함시켜야 합니다.
- bos token id
- eos token id
- uknown token id
- seperate token id
- padding token id
- Vocab 파일
이외에도 추론기에 이 값을 활용하는 기능이나 필요한 정보가 있다면 구현이 되어있어야 합니다.
magic = 0x46554747
version = 3
tensor_count = 291
metadata_kv_count = 16
general.architecture = llama
general.name = LLaMA
llama.context_length = 2048
llama.embedding_length = 4096
llama.block_count = 32
llama.feed_forward_length = 11008
llama.rope.dimension_count = 128
llama.attention.head_count = 32
llama.attention.head_count_kv = 32
llama.attention.layer_norm_rms_epsilon = 9.999999974752427e-07
general.file_type = 10
tokenizer.ggml.model = llama
tokenizer.ggml.tokens = ['<unk>', '<s>', '</s>', '<0x00>', '<0x01>', '<...
tokenizer.ggml.scores = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0...
tokenizer.ggml.token_type = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6...
general.quantization_version = 2
여기서 GGUF는 크게 세 분류로 나뉘어 지는데 1) Header 2) Tensor Info 3) Tensor Data Header에 메타데이터가 저장되어 있습니다. 그리고 Tensor Info와 Tensor Data 부분에 모델의 Weight Tensor 정보가 기록되어 있습니다.

다음 장에서는 추론기로 많이 사용하는 llama.cpp 실행 방법에 알아보도록 하겠습니다.
'머신러닝 & 딥러닝 > LLM' 카테고리의 다른 글
| [LLM] 기업용 특화 LLM 생성 방법 (0) | 2024.04.05 |
|---|---|
| [LLM]llama.cpp 실행방법 (0) | 2024.03.08 |
| [LLM]LangChain이란 무엇인가? (0) | 2023.12.02 |
| Andrew Ng(앤드류 응) 프롬프트 엔지니어링 강의 요약(4) (0) | 2023.09.20 |
| Andrew Ng(앤드류 응) 프롬프트 엔지니어링 강의 요약(3) (0) | 2023.09.19 |